Para que se possa obter a compreensão do que é software (e, em última análise, uma compreensão da engenharia de software), é importante examinar as características do software que o tornam diferente das outras coisas que os seres humanos constroem. Quando o hardware é construído, o processo criativo humano (análise, projeto, construção e teste) é imediatamente traduzido numa forma física. Se construimos um novo computador, nossos esboços iniciais, desenhos de projeto formais e protótipo em forma de breadboard (arranjo experimental de circuitos eletrônicos) evoluem para um produto físico (chips VLSI, placas de circuito, fontes de energia etc.). O software é um elemento de sistema lógico, e não físico. Portanto, o software tem características que são consideravelmente diferentes das do hardware.
1. O software é desenvolvido ou projetado por engenharia, não manufaturado no sentido clássico
Não obstante existam algumas semelhanças entre o desenvolvimento de software e a manufatura de hardware, as duas atividades são fundamentalmente diferentes. Em ambas atividades, a alta qualidade é obtida mediante um bom projeto, mas a fase de manufatura do hardware pode introduzir problemas de qualidade que inexistem (ou são facilmente corrigidos) para o software. Ambas atividades dependem de pessoas, mas a relacão entre as pessoas envolvidas e o trabalho executado é inteiramente diferente. Ambas atividades exigem a construção de um "produto", mas as abordagens são muito diferentes. Os custos do software estão concentrados no trabalho de engenharia. Isto significa que os projetos de software não podem ser geridos como se fossem projetos de manufatura. No decorrer da década passada, o conceito de "fábrica de software" foi discutido na literatura [1,2]. Torna-se importante observar que este termo não implica que a manufatura de hardware e o desenvolvimento de software sejam equivalentes. Ao contrário, o conceito de fábrica de software recomenda o uso de ferramentas automatizadas para o desenvolvimento de software.
2. O software não se "desgasta"
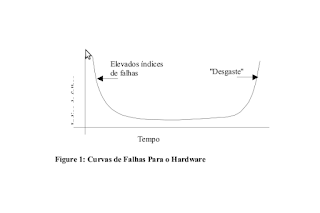
A Figura 1 mostra o índice de falhas como uma função do tempo para o hardware. A relação, muitas vezes chamada "curva da banheira", indica que o hardware exibe índices de falhas relativamente elevados logo no começo de seu ciclo de vida (estas falhas frequentemente são atribuídas a defeitos de projeto e manufatura); os defeitos são corrigidos e o indice de falhas cai para um nível estável (esperançosamente, muito baixo) durante certo período de tempo. À medida que o tempo passa, entretanto, o índice de falhas eleva-se novamente conforme os componentes de hardware sofrem os efeitos cumulativos de poeira, vibração, abuso, temperaturas extremas e muitos outros males ambientais. Colocado de maneira simples o hardware começa a se desgastar.
O software não é sensível aos problemas ambientais que fazem com que o hardware se desgaste. Teoricamente, portanto, a curva do índice de falhas para o software assumiria a forma representada na Figura 2. Defeitos não descobertos provocarão elevados índices de falhas no começo da vida de um programa. Porém esses são corrigidos (espera-se que novos erros não sejam introduzidos) e a curva achata-se, como mostra a Figura 2. Esta figura representa de forma grosseira e simplificada os modelos de falhas reais para o software. Entretanto fica claro que o software não se desgasta. Todavia se deteriora!
Esta aparente contradição pode ser mais bem explicada considerando a Figura 3. Durante sua vida, o software enfrentará mudancas (manutenção). Quando estas são feitas, é provável que novos defeitos sejam introduzidos, fazendo com que a curva do índice de falhas apresente picos, como mostrado na Figura 3:
Outro aspecto do uso ilustra a diferença entre o hardware e o software. Quando se desgasta, um componente de hardware é substituído por uma "peça de reposição. Não existem peças de reposição para o software. Toda falha de software indica um erro de projeto ou no processo por meio do qual o projeto foi traduzido em código executável por máquina. Portanto a manutenção do software envolve consideravelmente mais complexidade do que a manutenção de hardware.
3. A maioria dos software é feita sob medida em vez de ser montada a partir de componentes existentes.
Consideremos a maneira segundo a qual o hardware de controle para um produto baseado em microprocessadores é projetado e construído. O engenheiro de projetos desenha um esquema simples do circuito digital, faz algumas análises fundamentais para garantir que a função adequada seja conseguida e depois vai a estante onde existm catálogos de componenentes digitais. Cada circuito integrado (CI ou chip) tem uma numeração de peça, uma função definida e validada, uma interface bem definida e um conjunto padrão de diretrizes de integração. Depois que cada componente é escolhido, o hardware pode ser encomendado. Infelizmente, os projetistas de software não podem permitir-se ao que acabamos de descrever. Com poucas exceções, não existem catálogos de componentes de software. É possível encomendar software não destinado à publicação, mas somente como uma unidade completa, não como componente que possa ser montado novamente em novos programas, embora esta situação esteja em mudança com a difusão do uso de programação orientada a objeto, cujo resultado são as "CIs de Software". Ainda que muita coisa tenha sido escrita sobre reusabilidade de software, somente agora começam a aparecer as primeiras tentativas bem sucedidas.
COMPONENTES DO SOFTWARE
O software de computador é uma informação que existe em duas formas básicas: componentes não executáveis em máquina e componentes executáveis em máquina. Para o propósito de nossa discussão aqui, somente os componenentes de software que levam diretamente a instruções executáveis em máquina serão apresentados. Os componentes de software são criados por meio de uma série de conversões que mapeiam as exigências de clientes para código executável em máquina. Um modelo (ou protótipo) das exigências é convertido num projeto. O projeto de software é convertido em uma linguagem que especifica a estrutura de dados do software, os atributos procedimentais e os requisitos relacionados. A forma de linguagem é processada por um tradutor que a converte em instruções executáveis em máquina. A reusabilidade é uma caracerística importante de um componente de software de alta qualidade [3]. Ou seja, o componente deve ser projetado e implementado de forma que possa ser reusado em muitos programas diferentes. Na década de 1960, foram construídas bibliotecas de sub-rotinas científicas que eram reusáveis num amplo conjunto de aplicações científicas e de engenharia. Estas bibliotecas de sub-rotinas reusavam algoritmos bem definidos efetivamente, mas tinham um domínio de aplicação limitado. Atualmente ampliamos nossa visão do reuso a fim de envolver não apenas algoritmos mas também estruturas de dados. Um componente resusável na década de 1990 engloba tanto dados como processamento num único pacote (às vezes chamado classe ou objeto), possibilitando que o engenheiro de software crie novas aplicações a partir de partes reusáveis. Por exemplo as interfaces interativas de hoje frequentemente são construídas utilizando-se componentes reusáveis que possibilitam a criação de janelas gráficas, menus pull-down e uma ampla variedade de mecanismos de interação. As estruturas de dados e detalhes de processamento exigidos para se construir a interface com os usuários estão contidas numa biblioteca de componentes reusáveis pra construção de interfaces.
Os componentes de software são construídos usando uma linguagem de programação que tem um vocabulário limitado, uma gramática explicitamente definita e regras de sintaxe e semântica bem formadas. Esses atributos são essenciais para a tradução por máquina. As formas de linguagem em uso são linguagens de máquina, linguagens de alto nível e linguagens não-procedimentais. A linguagem de máquina é uma represetação simbólica do conjunto de instruções da Unidade Central de Processamento (CPU - Central Processing Unity). Quando um bom desenvolvedor de software produz um programa bem documentado, capaz de sofrer manutencção, a linguagem de máquina pode fazer um uso extremamente eficiente da memória e otimizar a velocidade de execução do programa. Quando um programa é projetado pobremente e tem pouca documentação, a linguagem de máquina é um pesadelo. As linguagens de alto nível permitem que o desenvolvedor de software e o programa sejam independentes da máquina. Quando é usado um tradutor mais sofisticado, o vocabulário, a gramática, a sintaxe e a semântica de uma linguagem de alto nível podem ser muito mais sofisticados do que as linguagens de nível de máquina. De fato, os compiladores e os interpretadores de linguagem de alto nível produzem como saída uma linguagem de máquina. Não obstante centenas de linguagens de progamação estejam em uso atualmente pouco mais do que 10 linguagens de programação de alto nível são amplamente usadas na indústria. Linguagens tais como o COBOL e FORTRAN continuam tendo um uso generalizado quase 30 anos depois de sua introdução. Linguagens de programação modernas tais como Pascal, C e Ada estão sendo amplamente usadas. Linguagens orientadas a objetos, tais como C++, Object Pascal, Eiffel e outras estão conquistando entuasiásticos seguidores. Linguagens especializadas tais como APL, LISP, OPS5, Prolog e linguagens descritivas podem para redes neurais artificiais estão conquistando maior aceitação à medida novas abordagens de aplicação saem do laboratório para o uso prático. As linguagens de máquina, as linguagens montadoras (Assembly) e as linguagens de programação de alto nível frequentemente são citadas como "as tres primeiras gerações" das linguagens de computador. Com todas estas linguagens, o programador deve preocupar-se tanto com a especificação da estrutura de informações como com o controle do programa em si. Daí as linguagens das três primeiras geracões serem domiadas linguagens procedimentais. No decorrer da última década, um grupo de linguagens de quarta geração, ou não-procedimentais, foi introduzida. Em vez de exigir que o desenvolvedor de software especifique detalhes de procedimentos, a linguagem nao-procedimental subentendo um programa "especificando o resultado desejado, em vez de especificar a ação exigida para se conseguir esse resultado" [4]. O software de apoio converte a especificação do resultado numprogram executável em máquina.
Texto extraído com pequenas adaptações de:
Presman, R.S.; Engenharia de Software, Makron books, S.P., 1995, pags. 13-19

















