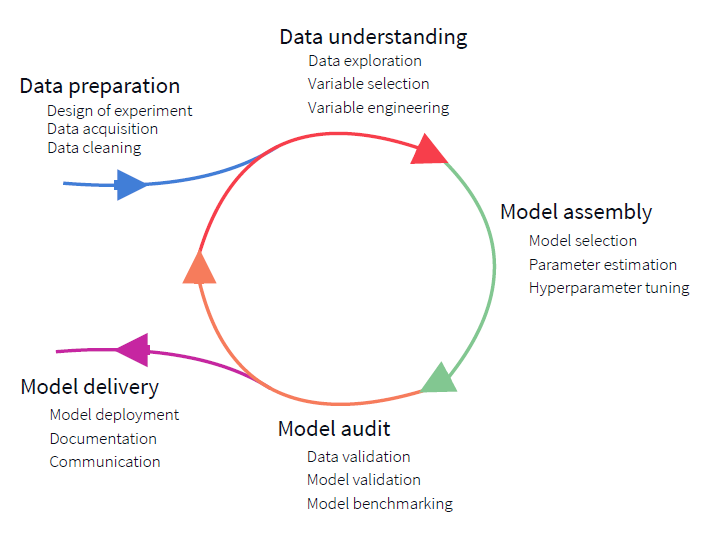
Code should work
This one is so obvious that it probably doesn’t need stating, but I’ll go ahead and say it anyway. When we write code, we are trying to solve a problem, such as implementing a feature, fixing a bug, or performing a task. The primary aim of our code is that it should work: it should solve the problem that we intend it to solve. This also implies that the code is bug free, because the presence of bugs will likely prevent it from working properly and fully solving the problem.
When defining what code “working” means, we need to be sure to actually capture all the requirements. For example, if the problem we are solving is particularly sensitive to performance (such as latency, or CPU usage), then ensuring that our code is adequately performant comes under “code should work,” because it’s part of the requirements. The same applies to other important considerations such as user privacy and security.
Code should keep working
Code “working” can be a very transient thing; it might work today, but how do we make sure that it will still be working tomorrow, or in a year’s time? This might seem like an odd question: “if nothing changes, then why would it stop working?”, but the point is that stuff changes all the time:
Code that works today but breaks tomorrow when one of these things changes is not very useful. It’s often easy to create code that works, but a lot harder to create code that keeps working. Ensuring that code keeps working is one of the biggest considerations that software engineers face, and is something that needs to be considered at all stages of coding. Considering it as an afterthought, or just assuming that adding some tests later on will achieve this are often not effective approaches.
Code should be adaptable to changing requirements
It’s actually quite rare that a piece of code is written once and then never modified again. Continued development on a piece of software can span several months, usually several years, and sometimes even decades. Throughout this process requirements change:
Deciding how much effort to put into making code adaptable can be a tricky balancing act. On the one hand, we pretty much know that the requirements for a piece of software will evolve over time (it’s extremely rare that they don’t). But on the other hand, we often have no certainty about exactly how they will evolve. It’s impossible to make perfectly accurate predictions about how a piece of code or software will change over time. But just because we don’t know exactly how something will evolve, it doesn’t mean that we should completely ignore the fact that it will evolve. To illustrate this, let’s consider two extreme scenarios:
Scenario A and scenario B represent two opposing extremes. The outcome in both scenarios is quite bad and neither is an effective way to create software. Instead, we need to find an approach somewhere in the middle of these two extremes. There’s no single answer for which point on the spectrum between scenario A and scenario B is optimal. It will depend on the kind of project we’re working on and on the culture of the organization we work for.
Code should not reinvent the wheel
When we write code to solve a problem, we generally take a big problem and break it down into many subproblems. For example, if we were writing some code to load an image file, turn into a grayscale image, and then save it again, the subproblems we need to solve are:
Many of these problems have already been solved by others, for example loading some bytes from a file is likely something that the programming language has built in support for. We wouldn’t go and write our own code to do low-level communication with the file system.
Similarly, there is probably an existing library that we can pull in to parse the bytes into an image. If we do write our own code to do low-level communication with the file system or to parse some bytes into an image, then we are effectively reinventing the wheel. There are several reasons why it’s best to make use of an existing solution over reinventing it:
The concept of not reinventing the wheel applies in both directions. If another engineer has already written code to solve a subproblem, then we should call their code rather than writing our own to solve it. But similarly, if we write code to solve a subproblem, then we should structure our code in a way that makes it easy for other engineers to reuse, so they don’t need to reinvent the wheel.
The same classes of subproblems often crop up again and again, so the benefits of sharing code between different engineers and teams are often realized very quickly.




A typical plot diagram for an action movie can be similar to a the narrative structure of a scientific presentation. Just as a protagonist overcomes obstacles through a series of action scenes, a scientist pursues scientific objectives through a series of experiments to reach a goal. As a scientist comes closer and closer to reaching a goal, curiosity comes to a maximal point, the initial scientific question is answered, and the presentation reaches a sense of resolution.
The Zen of Python—a collection of principles that summarize the core philosophy of the language—has crystal-clear points like these:
If the implementation is easy to explain, it may be a good idea.
Data integrity refers to the physical characteristics of collected data that determine the reliability of the information. Data integrity is based on parameters such as completeness, uniqueness, timeliness, accuracy, and consistency.
Completeness
Data completeness refers to collecting all items necessary to the full description of the states of a considered object or process. A data item is considered complete if its digital description contains all attributes that are strictly required for human or machine comprehension. In other words, it may be acceptable to have missing pieces in the expected records (i.e., no contact information) as long as the remaining data is comprehensive enough for the domain.
For example, when a sensor (e.g., an IoT sensor) is involved, you might want it to sample data at a frequency of 10 minutes or even less if required or appropriate for the scenario. At the same time, you might want to be sure that the timeline is continuous with no gaps in between. If you plan to use that data to predict possible hardware failures, then you need be sure you can keep an eye close enough to the target event and not miss anything along the way.
Completeness results from having no gaps in the data from what was supposed to be collected and what is actually collected. In automatic data collection (i.e., IoT sensors), this aspect is also related to physical connectivity and data availability.
Uniqueness
When large chunks of data are collected and sampled for further use, there’s the concrete risk that some data items are duplicated. Depending on the business requirements, duplicates may or may not be an issue. Poor data uniqueness is an issue if, for example, it could lead to skewed results and inaccuracies.
Uniqueness is fairly easy to define mathematically. It is 100 percent if there are no duplicates. The definition of duplicates, however, depends on the context. For example, two records about Joseph Doe and Joe Doe are apparently unique but may refer to the same individual and then be duplicates that must be cleaned.
Timeliness
Data timeliness refers to the distribution of data records within an acceptable time frame. The definition of an acceptable time frame is also context-specific. It refers to the duration of the time frame and the appropriate timeline.
In predictive maintenance, for example, the timeline varies depending on the industry. Usually, a 10-minute timeline is more than acceptable but not for reliable fault predictions in wind turbines. In this case, a 5-minute interval is debated, and some experts suggest an even shorter rate of data collection.
Duration is the overall time interval for which data collection should occur to ensure reliable analysis of data and satisfactory results. In predictive maintenance, an acceptable duration is on the order of two years’ worth of data.
Accuracy
Data accuracy measures the degree to which the record correctly describes the observed real-world item. Accuracy is primarily about the correctness of the data acquired. The business requirements set the specifications of what would be a valid range of values for any expected data item.
When inaccuracies are detected, some policies should be applied to minimize the impact on decisions. Common practices are to replace out-of-range values with a default value or with the arithmetic mean of values detected in a realistic interval.
Consistency
Data consistency measures the difference between the values reported by data items that represent the same object. An example of inconsistency is a negative value of output when no other value reports failures of any kind. Definitions of data consistency are, however, also highly influenced by business requirements.

The classification problem is about identifying the category an object belongs to. In this context, an object is a data item and is fully represented by an array of values (known as features). Each value refers to a measurable property that makes sense to consider in the scenario under analysis. It is key to note that classification can predict values only in a discrete, categorical set.

Variations of the Problem
The actual rules that govern the object-to-category mapping process lead to slightly different variations of the classification problem and subsequently different implementation tasks.
Binary Classification. The algorithm has to assign the processed object to one of only two possible categories. An example is deciding whether, based on a battery of tests for a particular disease, a patient should be placed in the “disease” or “no-disease” group.
Multiclass Classification. The algorithm has to assign the processed object to one of many possible categories. Each object can be assigned to one and only one category. For example, classifying the competency of a candidate, it can be any of poor/sufficient/good/great but not any two at the same time.
Multilabel Classification. The algorithm is expected to provide an array of categories (or labels) that the object belongs to. An example is how to classify a blog post. It can be about sports, technology, and perhaps politics at the same time.
Anomaly Detection. The algorithm aims to spot objects in the dataset whose property values are significantly different from the values of the majority of other objects. Those anomalies are also often referred to as outliers.

For data science and development teams to work together (and along with domain experts), it is necessary that skills tend to merge: data scientists learning about programming aspects and user experience and, more importantly, developers learning about the intricacies and internal mechanics of machine learning.


SAAS - Software as a Service
PAAS - Plataform as a Service
IAAS - Infrastructure as a Service
CAAS - Containers as a Service
FAAS - Function as a Service


A typical click farm equipment set up
Arguably the most important hyperparameter, the learning rate, roughly speaking, controls how fast your neural net “learns”. So why don’t we just amp this up and live life on the fast lane?
Not that simple. Remember, in deep learning, our goal is to minimize a loss function. If the learning rate is too high, our loss will start jumping all over the place and never converge.

And if the learning rate is too small, the model will take way too long to converge, as illustrated above.
Consistency defines the rules under which distributed data is available to users. What this means is that when new data is available (i.e., new, or updated data) in a distributed database, the consistency model determines when the data is available to users for reads. Besides strong and eventual, there are three additional consistency models. These are the bounded staleness, session, and consistent prefix.
Strong
Consistency Model
Guarantees that any read of an item (such as a customer record) will return the most recent version of such item.
Eventual
Consistency Model
When using the eventual consistency model, it is guaranteed that all the replicas will eventually converge to reflect the most recent write.
Bounded
Staleness Consistency Model
With bounded staleness, reads may lag writes by at most K operations or a t time interval. For an account with only one region, K must be between 10 and 1,000,000 operations, and between 100,000 and 1,000,000 operations if the account is globally distributed.
Session
Consistency Model
The session consistency model is named so because the consistency level is scoped at the client session. What this means is that any reads or writes are always current within the same session, and they are monotonic.
Consistent
Prefix Consistency Model
The last consistency model is consistent prefix. This model is like the eventual consistency model; however, it guarantees that reads never see out-of-order writes.
Consistency
for Queries
By default,
any user-defined resource would have the same consistency level for queries as
was defined for reads.