Showing posts with label governança de ti. Show all posts
Showing posts with label governança de ti. Show all posts
Friday, June 13, 2014
Wednesday, October 17, 2012
Alta Disponibilidade : O mito dos 99.999%

As
novas demandas dos negócios começam a exigir sistemas 24x7, disponíveis
sete dias por semana, vinte e quatro horas por dia. O tempo que estes
ssitemas podem ficar fora do ar são cuidadosamente definidos e
normalmente utilizam-se métricas que regem os contratos entre as áreas
fins e a área de TI.
Deve ficar claro que o negócio define o nível de disponibilidade necessária pois quanto maior a disponibilidade requerida maior o investimento em infra-estrutura.
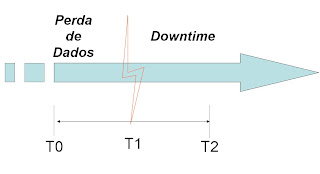
A figura abaixo representa um acidente no tempo T1 ocorrido em um determinado sistema. O tempo decorrido entre T1 e T2 é o tempo de downtime. O tempo T0 é o tempo de perda de dados durante o downtime. Quanto menor o tempo de downtime e menor o tempo de perda de dados maior a disponibilidade do sistema e maior o investimento em tecnologias que permitem a recuperação do site.
Deve ficar claro que o negócio define o nível de disponibilidade necessária pois quanto maior a disponibilidade requerida maior o investimento em infra-estrutura.
A figura abaixo representa um acidente no tempo T1 ocorrido em um determinado sistema. O tempo decorrido entre T1 e T2 é o tempo de downtime. O tempo T0 é o tempo de perda de dados durante o downtime. Quanto menor o tempo de downtime e menor o tempo de perda de dados maior a disponibilidade do sistema e maior o investimento em tecnologias que permitem a recuperação do site.
 A
Alta disponibilidade significa que o serviço de TI está continuamente
disponível para o cliente havendo pouco downtime e recuperação rápida. A
alta disponibilidade (HA) e a recuperação a desastres (DR) devem ser
pensadas como um continuum e acontecem em várias camadas , onde cada
camada propicia os níveis de disponibilidade adequado para a camada
superior.
A
Alta disponibilidade significa que o serviço de TI está continuamente
disponível para o cliente havendo pouco downtime e recuperação rápida. A
alta disponibilidade (HA) e a recuperação a desastres (DR) devem ser
pensadas como um continuum e acontecem em várias camadas , onde cada
camada propicia os níveis de disponibilidade adequado para a camada
superior.
A
alta disponibilidade hoje é considerada o principal SLA de qualquer
instalação de DATACENTER. Para se obter um nível de serviço adequado é
necessário que os componentes de toda a solução contribuam para a
obtenção deste nível de serviço.
Quase todo usuário de sistema quando interrogado sobre qual o SLA requerido sempre diz que é 100%, mas sabe-se que para muitas aplicações um SLA menor é mais do que suficiente e economico (ver artigo Porque ILM ? neste blog ). A disponibilidade que é percebida pelo usuário depende da quantidade de indisponibilidades, da duração da indisponibilidade e da quantidade de usuários afetados,A disponibilidade (ou a alta disponibilidade) de um sistema é calculada da seguinte forma:
Quase todo usuário de sistema quando interrogado sobre qual o SLA requerido sempre diz que é 100%, mas sabe-se que para muitas aplicações um SLA menor é mais do que suficiente e economico (ver artigo Porque ILM ? neste blog ). A disponibilidade que é percebida pelo usuário depende da quantidade de indisponibilidades, da duração da indisponibilidade e da quantidade de usuários afetados,A disponibilidade (ou a alta disponibilidade) de um sistema é calculada da seguinte forma:
 Onde
A é o grau de disponibilidade expresso em porcentagem, MTBF é o mean
time between failures e o MTTR é o maximum time to repair. Se um sistema
tem MTBF de 100.000 horas (mais que 11 anos) e o MTTR é de 1 hora , o
disponibilidade (A) é de 99.9999 %. Ou seja em 11 anos teremos neste caso 6 minutos de downtime.
Onde
A é o grau de disponibilidade expresso em porcentagem, MTBF é o mean
time between failures e o MTTR é o maximum time to repair. Se um sistema
tem MTBF de 100.000 horas (mais que 11 anos) e o MTTR é de 1 hora , o
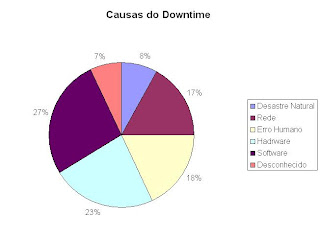
disponibilidade (A) é de 99.9999 %. Ou seja em 11 anos teremos neste caso 6 minutos de downtime.Há uma tendencia que o downtime (tempo que o sistema esta fora do ar) considerado por organizações que atuam 24x7 inclua a indisponibilidade planejada e a indisponibilidade não planejada. O downtime não planejado tem sua fonte principal na falha do software, segundo pesquisa realizada pelo Gartner/Dataquest e mostrada o gráfico abaixo.
A alta disponibilidade alcançada é indicada por métricas como mostrado na tabela abaixo.
É muito comum associar o nível de alta disponibilidade a percentagem de uptime que o sistema permite . Sistemas com cinco noves (99.999%) podem parar cinco minutos e 15 segundos ao longo do ano considerando inclusive as paradas programadas.
É muito comum associar o nível de alta disponibilidade a percentagem de uptime que o sistema permite . Sistemas com cinco noves (99.999%) podem parar cinco minutos e 15 segundos ao longo do ano considerando inclusive as paradas programadas.

Vejamos
o exemplo de um serviço fim a fim baseado em uma aplicação
client/server prometido por um fornecedor com 99.99% de disponibilidade.
Na verdade considerando todo o sistema é muito dificil ter um SLA desta
ordem. Vejamos o processo de realizar uma consulta a esta aplicação
client/server realizada por um usuário (na sua estação de trabalho - o
client). Entre os dois estão a estação do cliente, a rede LAN da
organização, a rede WAN, os servidores, a aplicação e finalmente o storage. Não estamos considerando alguns componentes para facilitar (firewall, switches, etc.)
 Para simplificar vamos considerar que existem sete componentes entre o client e o storage.
Se cada componente tiver 99.99% e assumirmos que as falhas não
acontecem ao mesmo tempo , o SLA final da cadeia é de 99.93%
(0.9999*0.9999*0.9999*0.9999*0.9999*0.9999*0.9999) que não representa 52
minutos parados no ano mais sim 6 horas ! That is the question !
Para simplificar vamos considerar que existem sete componentes entre o client e o storage.
Se cada componente tiver 99.99% e assumirmos que as falhas não
acontecem ao mesmo tempo , o SLA final da cadeia é de 99.93%
(0.9999*0.9999*0.9999*0.9999*0.9999*0.9999*0.9999) que não representa 52
minutos parados no ano mais sim 6 horas ! That is the question !Pois bem ! Este papo de sistemas fim a fim com cinco noves que teoricamente ficariam trinta e dois segundos fora do ar por ano é balela ! Outro aspecto importante é que o simples fato de um dos componentes da rede ter um SLA menor dispenca o SLA médio final. É só fazer a conta.
Algumas regras importantes:
1 - Investir em um único componente tem pouco impacto no SLA total;
1.00*.995*.995*.995=98.5% (sai de 99.5% para 98.5%
2- Um componente pouco confiável reduz consideravelmente o SLA total;
0.95*.995*.995*.995=98.5% (sai de 99.5% para 93,6%)
3- Melhor cuidar da cadeia de SLA inteira
0.9975*0.9975*0.9975*0.9975=99%
Referência:
[1]Marcus, Evan & Stern, Hal. Blueprints for High Availability, Second Edition, 2003.
[2]Jorge Luís Cordenonsi, Gerenciamento da Disponibilidade de TI, material disponível na Internet.
Sunday, August 07, 2011
Qual o problema de eu ter meu próprio data center?
Apesar a falta de profissionalismo no trato da micro-informática, quando estamos em um ambiente mais corporativo (mais de 10.000 usuários) temos certos problemas a considerar. Hoje em dia, criar e manter um datacenter exige muitos esforços.
* Escolher uma boa localização do data center;
* Instalar controle climatizado;
* Rack para os computadores;
* Controle de acesso;
* Sistema de supressão de fogo;
* Documentar as instalações físicas;
* Isolar usuários de administradores;
* Sistema redundante de energia elétrica;
* Cabeamento;
* Instalação de linha telefônica;
* Facilities;
Depois de implantado, você tem as tarefas de gerenciamento dos serviços:
* Aplicar patches do SO;
* Diagnosticar falhas de serviços;
* Administrar aumento de tráfego;
* Responder falhas de hardware;
* Adicionar capacidade de armazenamento;
* Upgrade online de novas funcionalidades;
E tudo isso seguindo boas práticas (ou governança de TI com alguns frameworks (ITIL, COBIT) para gerar transparência para os acionistas. Detalhe, não foi apresentando ainda questões relacionadas aos aplicativos suportados pela infra. Simples não?
* Escolher uma boa localização do data center;
* Instalar controle climatizado;
* Rack para os computadores;
* Controle de acesso;
* Sistema de supressão de fogo;
* Documentar as instalações físicas;
* Isolar usuários de administradores;
* Sistema redundante de energia elétrica;
* Cabeamento;
* Instalação de linha telefônica;
* Facilities;
Depois de implantado, você tem as tarefas de gerenciamento dos serviços:
* Aplicar patches do SO;
* Diagnosticar falhas de serviços;
* Administrar aumento de tráfego;
* Responder falhas de hardware;
* Adicionar capacidade de armazenamento;
* Upgrade online de novas funcionalidades;
E tudo isso seguindo boas práticas (ou governança de TI com alguns frameworks (ITIL, COBIT) para gerar transparência para os acionistas. Detalhe, não foi apresentando ainda questões relacionadas aos aplicativos suportados pela infra. Simples não?
Wednesday, December 22, 2010
CobiT
COBIT®, do inglês, Control Objectives for Information and related Technology, é um guia de boas práticas apresentado como framework, dirigido para a gestão de tecnologia de informação (TI). Mantido pelo ISACA (Information Systems Audit and Control Association), possui uma série de recursos que podem servir como um modelo de referência para gestão da TI, incluindo um sumário executivo, um framework, objetivos de controle, mapas de auditoria, ferramentas para a sua implementação e principalmente, um guia com técnicas de gerenciamento. Especialistas em gestão e institutos independentes recomendam o uso do CobiT como meio para otimizar os investimentos de TI, melhorando o retorno sobre o investimento (ROI) percebido, fornecendo métricas para avaliação dos resultados (Key Performance Indicators KPI, Key Goal Indicators KGI e Critical Success Factors CSF).
O CobiT independe das plataformas de TI adotadas nas empresas, tal como independe do tipo de negócio e do valor e participação que a tecnologia da informação tem na cadeia produtiva da empresa.
Em 28 de janeiro de 2010, foi anunciada oficialmente a tradução do COBIT 4.1 para a Língua Portuguesa.[1]
O CobiT independe das plataformas de TI adotadas nas empresas, tal como independe do tipo de negócio e do valor e participação que a tecnologia da informação tem na cadeia produtiva da empresa.
Em 28 de janeiro de 2010, foi anunciada oficialmente a tradução do COBIT 4.1 para a Língua Portuguesa.[1]
Information Technology Infrastructure Library
Information Technology Infrastructure Library (ITIL) é um conjunto de boas práticas a serem aplicadas na infraestrutura, operação e manutenção de serviços de tecnologia da informação (TI). Foi desenvolvido no final dos anos 1980 pela CCTA (Central Computer and Telecommunications Agency) e atualmente está sob custódia da OGC (Office for Government Commerce) da Inglaterra.
A ITIL busca promover a gestão com foco no cliente e na qualidade dos serviços de tecnologia da informação (TI). A ITIL lida com estruturas de processos para a gestão de uma organização de TI apresentando um conjunto abrangente de processos e procedimentos gerenciais, organizados em disciplinas, com os quais uma organização pode fazer sua gestão tática e operacional em vista de alcançar o alinhamento estratégico com os negócios.
ITIL dá uma descrição detalhada sobre importantes práticas de IT com checklists, tarefas e procedimentos que uma organização de IT pode customizar para suas necessidades.
A ITIL busca promover a gestão com foco no cliente e na qualidade dos serviços de tecnologia da informação (TI). A ITIL lida com estruturas de processos para a gestão de uma organização de TI apresentando um conjunto abrangente de processos e procedimentos gerenciais, organizados em disciplinas, com os quais uma organização pode fazer sua gestão tática e operacional em vista de alcançar o alinhamento estratégico com os negócios.
ITIL dá uma descrição detalhada sobre importantes práticas de IT com checklists, tarefas e procedimentos que uma organização de IT pode customizar para suas necessidades.
Subscribe to:
Posts (Atom)