A razão é que geralmente quando indagados sobre o que causa um problema, o ser humano tende a culpar alguma coisa ao invés de raciocinar e realmente procurar a causa.
Geralmente se diz que:
No 1º porquê, temos um sintoma
No 2º porquê, temos uma desculpa
No 3º porquê, temos um culpado
No 4º porquê, temos uma causa
No 5º porquê, temos a causa raíz
Saturday, December 20, 2014
Sunday, October 12, 2014
Sunday, October 05, 2014
Saturday, October 04, 2014
Sunday, September 21, 2014
















Saturday, September 06, 2014
Sunday, August 24, 2014
Saturday, August 09, 2014
Trinta dicas "infalíveis" para escrever bem
1. Deve-se evitar ao máx. a utiliz. de abrev. etc.
2. É desnecessário empregar estilo de escrita demasiadamente rebuscado. Tal prática advém de esmero excessivo que raia o exibicionismo narcisístico.
3. Anule aliterações altamente abusivas.
4. não esqueça as maiúsculas no início das frases.
5. Evite lugares-comuns como o diabo foge da cruz.
6. O uso de parênteses (mesmo quando for relevante) é desnecessário.
7. Estrangeirismos estão out; palavras de origem portuguesa estão in.
8. Evite o emprego de gíria, mesmo que pareça nice, sacou?? ...então valeu!
9. "Porra", palavras de baixo calão podem transformar seu texto numa "merda".
10. Nunca generalize: generalizar é um erro em todas as situações.
11. Evite repetir a mesma palavra, pois essa palavra vai ficar uma palavra repetitiva. A repetição da palavra vai fazer com que a palavra repetida desqualifique o texto em que a palavra se encontra repetida.
12. Não abuse das citações. Como costuma dizer um amigo meu: "Quem cita os outros não tem idéias próprias".
13. Frases incompletas podem causar
14. Não seja redundante, não é preciso dizer a mesma coisa de formas diferentes; isto é, basta mencionar cada argumento uma só vez, ou, por outras palavras, não repita a mesma idéia várias vezes.
15. Seja mais ou menos específico.
16. Frases com apenas uma palavra? Jamais!
17. A voz passiva deve ser evitada.
18. Utilize a pontuação corretamente especialmente o ponto e a vírgula pois a frase poderá ficar sem sentido será que ninguém mais sabe utilizar o ponto de interrogação
19. Quem precisa de perguntas retóricas?
20. Conforme recomenda a A.G.O.P, nunca use siglas desconhecidas.
21. Exagerar é cem milhões de vezes pior do que a moderação.
22. Evite mesóclises. Repita comigo: "mesóclises: evitá-las-ei!"
23. Analogias na escrita são tão úteis quanto chifres numa galinha.
24. Não abuse das exclamações! Nunca!!! O texto fica horrível!!!!!
25. Evite frases exageradamente longas pois estas dificultam a compreensão das idéias nelas contidas e, por conterem mais que uma idéia central, o que nem sempre torna o seu conteúdo acessível, forçam, dessa forma, o pobre leitor a separá-la nos seus diversos componentes de forma a torná-las compreensíveis, o que não deveria ser, afinal de contas, parte do processo da leitura, hábito que devemos estimular através do uso de frases mais curtas.
26. Cuidado com a hortografia, para não estrupar a língúa portuguêza.
27. Seja incisivo e coerente; ou não...
28. Não fique escrevendo (nem falando) no gerúndio. Você vai estar deixando seu texto pobre e estar causando ambigüidade, com certeza você vai estar deixando o conteúdo esquisito, vai estar ficando com a sensação de que as coisas ainda estão acontecendo. E como você vai estar lendo este texto, tenho certeza que você vai estar prestando atenção e vai estar repassando aos seus amigos, que vão estar entendendo e vão estar pensando em não estar falando dessa maneira irritante.
29. Outra barbaridade que tu deves evitar chê, é usar muitas expressões que acabem por denunciar a região onde tu moras... nada de mandar esse trem... vixi... entendeu, bichinho?
30. Não permita que seu texto acabe por rimar, porque senão ninguém irá agüentar, já que é insuportável o mesmo final escutar, o tempo todo sem parar.
fonte: http://guiadoestudante.abril.com.br/estudar/portugues/trinta-dicas-infaliveis-escrever-bem-735235.shtml
2. É desnecessário empregar estilo de escrita demasiadamente rebuscado. Tal prática advém de esmero excessivo que raia o exibicionismo narcisístico.
3. Anule aliterações altamente abusivas.
4. não esqueça as maiúsculas no início das frases.
5. Evite lugares-comuns como o diabo foge da cruz.
6. O uso de parênteses (mesmo quando for relevante) é desnecessário.
7. Estrangeirismos estão out; palavras de origem portuguesa estão in.
8. Evite o emprego de gíria, mesmo que pareça nice, sacou?? ...então valeu!
9. "Porra", palavras de baixo calão podem transformar seu texto numa "merda".
10. Nunca generalize: generalizar é um erro em todas as situações.
11. Evite repetir a mesma palavra, pois essa palavra vai ficar uma palavra repetitiva. A repetição da palavra vai fazer com que a palavra repetida desqualifique o texto em que a palavra se encontra repetida.
12. Não abuse das citações. Como costuma dizer um amigo meu: "Quem cita os outros não tem idéias próprias".
13. Frases incompletas podem causar
14. Não seja redundante, não é preciso dizer a mesma coisa de formas diferentes; isto é, basta mencionar cada argumento uma só vez, ou, por outras palavras, não repita a mesma idéia várias vezes.
15. Seja mais ou menos específico.
16. Frases com apenas uma palavra? Jamais!
17. A voz passiva deve ser evitada.
18. Utilize a pontuação corretamente especialmente o ponto e a vírgula pois a frase poderá ficar sem sentido será que ninguém mais sabe utilizar o ponto de interrogação
19. Quem precisa de perguntas retóricas?
20. Conforme recomenda a A.G.O.P, nunca use siglas desconhecidas.
21. Exagerar é cem milhões de vezes pior do que a moderação.
22. Evite mesóclises. Repita comigo: "mesóclises: evitá-las-ei!"
23. Analogias na escrita são tão úteis quanto chifres numa galinha.
24. Não abuse das exclamações! Nunca!!! O texto fica horrível!!!!!
25. Evite frases exageradamente longas pois estas dificultam a compreensão das idéias nelas contidas e, por conterem mais que uma idéia central, o que nem sempre torna o seu conteúdo acessível, forçam, dessa forma, o pobre leitor a separá-la nos seus diversos componentes de forma a torná-las compreensíveis, o que não deveria ser, afinal de contas, parte do processo da leitura, hábito que devemos estimular através do uso de frases mais curtas.
26. Cuidado com a hortografia, para não estrupar a língúa portuguêza.
27. Seja incisivo e coerente; ou não...
28. Não fique escrevendo (nem falando) no gerúndio. Você vai estar deixando seu texto pobre e estar causando ambigüidade, com certeza você vai estar deixando o conteúdo esquisito, vai estar ficando com a sensação de que as coisas ainda estão acontecendo. E como você vai estar lendo este texto, tenho certeza que você vai estar prestando atenção e vai estar repassando aos seus amigos, que vão estar entendendo e vão estar pensando em não estar falando dessa maneira irritante.
29. Outra barbaridade que tu deves evitar chê, é usar muitas expressões que acabem por denunciar a região onde tu moras... nada de mandar esse trem... vixi... entendeu, bichinho?
30. Não permita que seu texto acabe por rimar, porque senão ninguém irá agüentar, já que é insuportável o mesmo final escutar, o tempo todo sem parar.
fonte: http://guiadoestudante.abril.com.br/estudar/portugues/trinta-dicas-infaliveis-escrever-bem-735235.shtml
Friday, August 01, 2014

Sunday, July 13, 2014


Saturday, July 05, 2014
Wednesday, July 02, 2014
Facts and Fallacies of Software Engineering
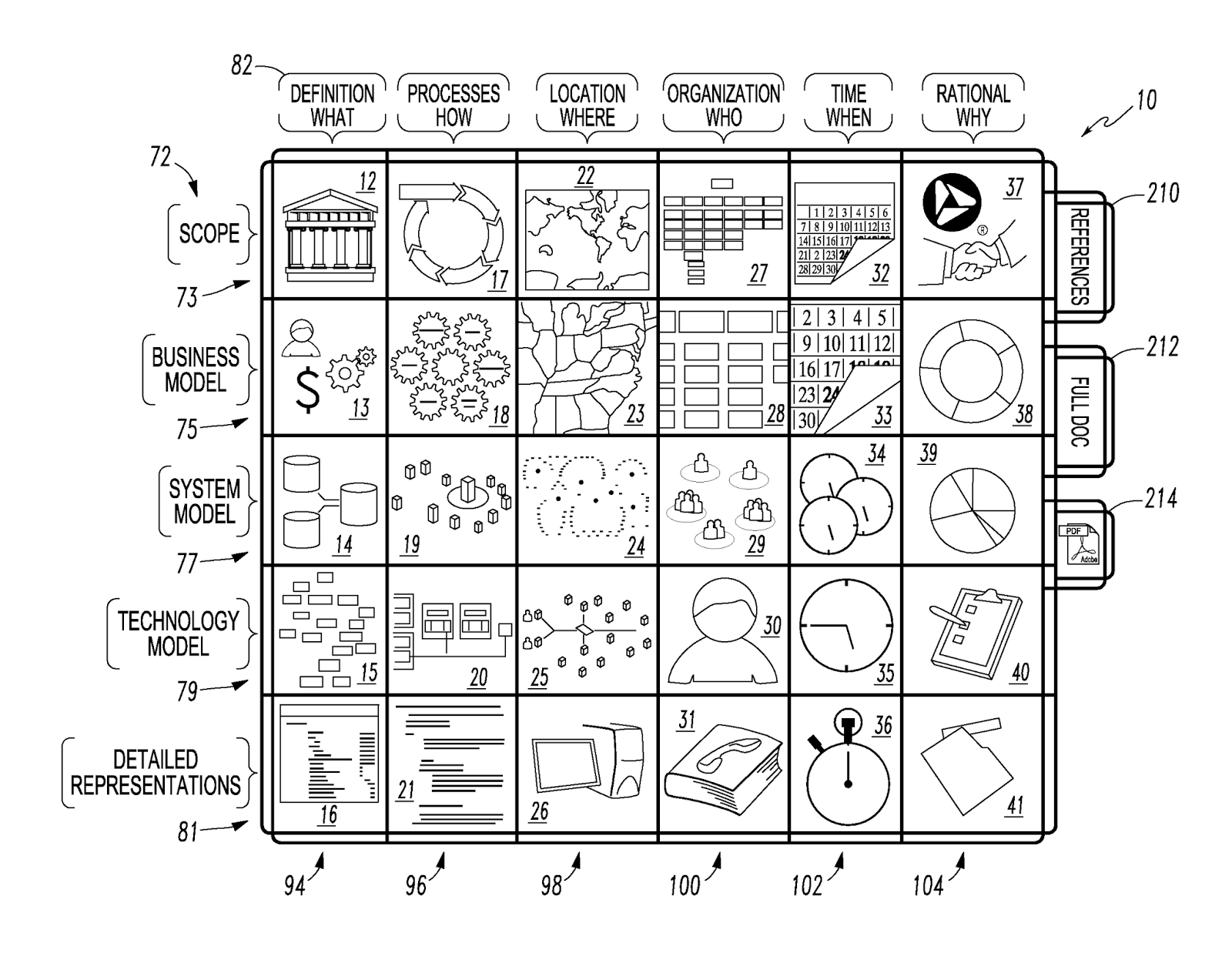
About Management
People
#Fact 1 - The most important factor in software work is not the tools and techniques used by the programmers, but rather the quality of the programmers themselves.
#Fact 2 - The best programmers are up to 28 times better than the worst programmers, according to "individual differences" research. Given that their pay is never commensurate, they are the biggest bargains in the software field.
#Fact 3 - Adding people to a late project makes it later.
#Fact 4 - The working environment has a profound impact on productivity and product quality.
Tools and Techniques
#Fact 5 - Hype is the plague on the house of software. Most software tool and technique improvements account for about a 5 to 35 percent increase in productivity and quality. But at one time or another, most of those same improvements have been claimed by someone to have "order of magnitude" benefits.
#Fact 6 - Learning a new tool or technique actually lowers programmer productivity and product quality initially. The eventual benefit is achieved only after this learning curve is overcome. Therefore, it is worth adopting new tools and techniques, but only (a) if their value is seen realistically and (b) if patience is used in measuring benefits.
#Fact 7 - Software developers talk a lot about tools. They evaluate quite a few, buy a fair number, and use practically none.
Estimation
#Fact 8 - One of the two most common causes of runaway projects is poor estimation.
#Fact 9 - Most software estimates are performed at the beginning of the life cycle. This makes sense until we realize that estimates are obtained before the requirements are defined and thus before the problem is understood. Estimation, therefore, usually occurs at the wrong time.
#Fact 10 - Most software estimates are made either by upper management or by marketing, not by the people who will build the software or their managers. Estimation is, therefore, done by the wrong people.
#Fact 11 - Software estimates are rarely adjusted as the project proceeds. Thus those estimates done at the wrong time by the wrong people are usually not corrected.
#Fact 12 - Since estimates are so faulty, there is little reason to be concerned when software projects do not meet estimated targets. But everyone is concerned anyway
#Fact 13 - There is a disconnect between management and their programmers. In one research study of a project that failed to meet its estimates and was seen by its management as a failure, the technical participants saw it as the most successful project they had ever worked on.
#Fact 14 - The answer to a feasibility study is almost always "yes."
Reuse
#Fact 15 - Reuse-in-the-small (libraries of subroutines) began nearly 50 years ago and is a well-solved problem.
#Fact 16 - Reuse-in-the-large (components) remains a mostly unsolved problem, even though everyone agrees it is important and desirable.
#Fact 17 - Reuse-in-the-large works best in families of related systems and thus is domain-dependent. This narrows the potential applicability of reuse-in-the-large.
#Fact 18 - There are two "rules of three" in reuse: (a) It is three times as difficult to build reusable components as single use components, and (b) a reusable component should be tried out in three different applications before it will be sufficiently general to accept into a reuse library.
#Fact 19 - Modification of reused code is particularly error-prone. If more than 20 to 25 percent of a component is to be revised, it is more efficient and effective to rewrite it from scratch.
#Fact 20 - Design pattern reuse is one solution to the problems inherent in code reuse.
Complexity
#Fact 21 - For every 25 percent increase in problem complexity, there is a 100 percent increase in complexity of the software solution. That's not a condition to try to change (even though reducing complexity is always a desirable thing to do); that's just the way it is.
#Fact 22 -Eighty percent of software work is intellectual. A fair amount of it is creative. Little of it is clerical.
About the Life Cycle
Requirements
#Fact 23 - One of the two most common causes of runaway projects is unstable requirements
#Fact 24 - Requirements errors are the most expensive to fix when found during production but the cheapest to fix early in development.
#Fact 25 - Missing requirements are the hardest requirements errors to correct.
Design
#Fact 26 - When moving from requirements to design, there is an explosion of "derived requirements" (the requirements for a particular design solution) caused by the complexity of the solution process. The list of these design requirements is often 50 times longer than the list of original requirements.
#Fact 27 - There is seldom one best design solution to a software problem.
#Fact 28 - Design is a complex, iterative process. The initial design solution will likely be wrong and certainly not optimal.
Coding
#Fact 29 - Programmers shift from design to coding when the problem is decomposed to a level of "primitives" that the designer has mastered. If the coder is not the same person as the designer, the designer's primitives are unlikely to match the coder's primitives, and trouble will result.
#Fact 30 - COBOL is a very bad language, but all the others (for business data processing) are so much worse.
Error Removal
#Fact 31 - Error removal is the most time-consuming phase of the life cycle.
Testing
#Fact 32 - Software that a typical programmer believes to be thoroughly tested has often had only about 55 to 60 percent of its logic paths executed. Using automated support, such as coverage analyzers, can raise that roughly to 85 to 90 percent. It is nearly impossible to test software at the level of 100 percent of its logic paths.
#Fact 33 - Even if 100 percent test coverage were possible, that is not a sufficient criterion for testing. Roughly 35 percent of software defects emerge from missing logic paths, and another 40 percent from the execution of a unique combination of logic paths. They will not be caught by 100 percent coverage.
#Fact 34 - It is nearly impossible to do a good job of error removal without tools. Debuggers are commonly used, but others, such as coverage analyzers, are not.
#Fact 35 - Test automation rarely is. That is, certain testing processes can and should be automated. But there is a lot of the testing activity that cannot be automated.
#Fact 36 - Programmer-created built-in debug code, preferably optionally included in the object code based on compiler parameters, is an important supplement to testing tools
Reviews and Inspections
#Fact 37 - Rigorous inspections can remove up to 90 percent of errors from a software product before the first test case is run
#Fact 38 - In spite of the benefits of rigorous inspections, they cannot and should not replace testing.
#Fact 39 - Postdelivery reviews (some call them "retrospectives") are generally acknowledged to be important, both from the point of view of determining customer satisfaction and from the point of view of process improvement. But most organizations do not do postdelivery reviews.
#Fact 40 - Peer reviews are both technical and sociological. Paying attention to one without the other is a recipe for disaster
Maintenance
#Fact 41 - Maintenance typically consumes 40 to 80 percent (average, 60 percent) of software costs. Therefore, it is probably the most important life cycle phase of software.
#Fact 42 - Enhancement is responsible for roughly 60 percent of software maintenance costs. Error correction is roughly 17 percent. Therefore, software maintenance is largely about adding new capability to old software, not fixing it.
#Fact 43 - Maintenance is a solution, not a problem.
#Fact 44 - In examining the tasks of software development versus software maintenance, most of the tasks are the same—except for the additional maintenance task of "understanding the existing product." This task consumes roughly 30 percent of the total maintenance time and is the dominant maintenance activity. Thus it is possible to claim that maintenance is a more difficult task than development.
#Fact 45 - Better software engineering development leads to more maintenance, not less.
About Quality
Quality
#Fact 46 - Quality is a collection of attributes.
#Fact 47 - Quality is not user satisfaction, meeting requirements, meeting cost and schedule targets, or reliability.
Reliability
#Fact 48 - There are errors that most programmers tend to make.
#Fact 49 - Errors tend to cluster.
#Fact 50 - There is no single best approach to software error removal.
#Fact 51 - Residual errors will always persist. The goal should be to minimize or eliminate severe errors.
#Fact 52 - Efficiency stems more from good design than from good coding.
#Fact 53 - High-order language (HOL) code, with appropriate compiler optimizations, can be about 90 percent as efficient as the comparable assembler code. Or even higher, for some complex modern architectures.
#Fact 54 - There are tradeoffs between size and time optimization. Often, improving one degrades the other.
About Research
#Fact 55 - Many software researchers advocate rather than investigate. As a result, (a) some advocated concepts are worth far less than their advocates believe, and (b) there is a shortage of evaluative research to help determine what the value of such concepts really is.
People
#Fact 1 - The most important factor in software work is not the tools and techniques used by the programmers, but rather the quality of the programmers themselves.
#Fact 2 - The best programmers are up to 28 times better than the worst programmers, according to "individual differences" research. Given that their pay is never commensurate, they are the biggest bargains in the software field.
#Fact 3 - Adding people to a late project makes it later.
#Fact 4 - The working environment has a profound impact on productivity and product quality.
Tools and Techniques
#Fact 5 - Hype is the plague on the house of software. Most software tool and technique improvements account for about a 5 to 35 percent increase in productivity and quality. But at one time or another, most of those same improvements have been claimed by someone to have "order of magnitude" benefits.
#Fact 6 - Learning a new tool or technique actually lowers programmer productivity and product quality initially. The eventual benefit is achieved only after this learning curve is overcome. Therefore, it is worth adopting new tools and techniques, but only (a) if their value is seen realistically and (b) if patience is used in measuring benefits.
#Fact 7 - Software developers talk a lot about tools. They evaluate quite a few, buy a fair number, and use practically none.
Estimation
#Fact 8 - One of the two most common causes of runaway projects is poor estimation.
#Fact 9 - Most software estimates are performed at the beginning of the life cycle. This makes sense until we realize that estimates are obtained before the requirements are defined and thus before the problem is understood. Estimation, therefore, usually occurs at the wrong time.
#Fact 10 - Most software estimates are made either by upper management or by marketing, not by the people who will build the software or their managers. Estimation is, therefore, done by the wrong people.
#Fact 11 - Software estimates are rarely adjusted as the project proceeds. Thus those estimates done at the wrong time by the wrong people are usually not corrected.
#Fact 12 - Since estimates are so faulty, there is little reason to be concerned when software projects do not meet estimated targets. But everyone is concerned anyway
#Fact 13 - There is a disconnect between management and their programmers. In one research study of a project that failed to meet its estimates and was seen by its management as a failure, the technical participants saw it as the most successful project they had ever worked on.
#Fact 14 - The answer to a feasibility study is almost always "yes."
Reuse
#Fact 15 - Reuse-in-the-small (libraries of subroutines) began nearly 50 years ago and is a well-solved problem.
#Fact 16 - Reuse-in-the-large (components) remains a mostly unsolved problem, even though everyone agrees it is important and desirable.
#Fact 17 - Reuse-in-the-large works best in families of related systems and thus is domain-dependent. This narrows the potential applicability of reuse-in-the-large.
#Fact 18 - There are two "rules of three" in reuse: (a) It is three times as difficult to build reusable components as single use components, and (b) a reusable component should be tried out in three different applications before it will be sufficiently general to accept into a reuse library.
#Fact 19 - Modification of reused code is particularly error-prone. If more than 20 to 25 percent of a component is to be revised, it is more efficient and effective to rewrite it from scratch.
#Fact 20 - Design pattern reuse is one solution to the problems inherent in code reuse.
Complexity
#Fact 21 - For every 25 percent increase in problem complexity, there is a 100 percent increase in complexity of the software solution. That's not a condition to try to change (even though reducing complexity is always a desirable thing to do); that's just the way it is.
#Fact 22 -Eighty percent of software work is intellectual. A fair amount of it is creative. Little of it is clerical.
About the Life Cycle
Requirements
#Fact 23 - One of the two most common causes of runaway projects is unstable requirements
#Fact 24 - Requirements errors are the most expensive to fix when found during production but the cheapest to fix early in development.
#Fact 25 - Missing requirements are the hardest requirements errors to correct.
Design
#Fact 26 - When moving from requirements to design, there is an explosion of "derived requirements" (the requirements for a particular design solution) caused by the complexity of the solution process. The list of these design requirements is often 50 times longer than the list of original requirements.
#Fact 27 - There is seldom one best design solution to a software problem.
#Fact 28 - Design is a complex, iterative process. The initial design solution will likely be wrong and certainly not optimal.
Coding
#Fact 29 - Programmers shift from design to coding when the problem is decomposed to a level of "primitives" that the designer has mastered. If the coder is not the same person as the designer, the designer's primitives are unlikely to match the coder's primitives, and trouble will result.
#Fact 30 - COBOL is a very bad language, but all the others (for business data processing) are so much worse.
Error Removal
#Fact 31 - Error removal is the most time-consuming phase of the life cycle.
Testing
#Fact 32 - Software that a typical programmer believes to be thoroughly tested has often had only about 55 to 60 percent of its logic paths executed. Using automated support, such as coverage analyzers, can raise that roughly to 85 to 90 percent. It is nearly impossible to test software at the level of 100 percent of its logic paths.
#Fact 33 - Even if 100 percent test coverage were possible, that is not a sufficient criterion for testing. Roughly 35 percent of software defects emerge from missing logic paths, and another 40 percent from the execution of a unique combination of logic paths. They will not be caught by 100 percent coverage.
#Fact 34 - It is nearly impossible to do a good job of error removal without tools. Debuggers are commonly used, but others, such as coverage analyzers, are not.
#Fact 35 - Test automation rarely is. That is, certain testing processes can and should be automated. But there is a lot of the testing activity that cannot be automated.
#Fact 36 - Programmer-created built-in debug code, preferably optionally included in the object code based on compiler parameters, is an important supplement to testing tools
Reviews and Inspections
#Fact 37 - Rigorous inspections can remove up to 90 percent of errors from a software product before the first test case is run
#Fact 38 - In spite of the benefits of rigorous inspections, they cannot and should not replace testing.
#Fact 39 - Postdelivery reviews (some call them "retrospectives") are generally acknowledged to be important, both from the point of view of determining customer satisfaction and from the point of view of process improvement. But most organizations do not do postdelivery reviews.
#Fact 40 - Peer reviews are both technical and sociological. Paying attention to one without the other is a recipe for disaster
Maintenance
#Fact 41 - Maintenance typically consumes 40 to 80 percent (average, 60 percent) of software costs. Therefore, it is probably the most important life cycle phase of software.
#Fact 42 - Enhancement is responsible for roughly 60 percent of software maintenance costs. Error correction is roughly 17 percent. Therefore, software maintenance is largely about adding new capability to old software, not fixing it.
#Fact 43 - Maintenance is a solution, not a problem.
#Fact 44 - In examining the tasks of software development versus software maintenance, most of the tasks are the same—except for the additional maintenance task of "understanding the existing product." This task consumes roughly 30 percent of the total maintenance time and is the dominant maintenance activity. Thus it is possible to claim that maintenance is a more difficult task than development.
#Fact 45 - Better software engineering development leads to more maintenance, not less.
About Quality
Quality
#Fact 46 - Quality is a collection of attributes.
#Fact 47 - Quality is not user satisfaction, meeting requirements, meeting cost and schedule targets, or reliability.
Reliability
#Fact 48 - There are errors that most programmers tend to make.
#Fact 49 - Errors tend to cluster.
#Fact 50 - There is no single best approach to software error removal.
#Fact 51 - Residual errors will always persist. The goal should be to minimize or eliminate severe errors.
#Fact 52 - Efficiency stems more from good design than from good coding.
#Fact 53 - High-order language (HOL) code, with appropriate compiler optimizations, can be about 90 percent as efficient as the comparable assembler code. Or even higher, for some complex modern architectures.
#Fact 54 - There are tradeoffs between size and time optimization. Often, improving one degrades the other.
About Research
#Fact 55 - Many software researchers advocate rather than investigate. As a result, (a) some advocated concepts are worth far less than their advocates believe, and (b) there is a shortage of evaluative research to help determine what the value of such concepts really is.
Wednesday, June 25, 2014
Software Complexity
Software is more complex, for the effort and the expense required to construct it, than most artifacts produced by human endeavor. Assuming it costs $ 50 (USD) per line of code to construct a one - million line program (specify, design, implement, verify, validate, and deliver it), the resulting cost will be $ 50,000,000. While this is a large sum of money, it is a small fraction of the cost of constructing a complex spacecraft, a skyscraper, or a naval aircraft carrier.
Brooks says, “ Software entities are more complex for their size [emphasis added] than perhaps any other human construct, because no two parts are alike (at least
above the statement level). ” It is diffi cult to visualize the size of a software program because software has no physical attributes; however, if one were to print a one - million line program the stack of paper would be about 10 feet (roughly 3 meters) high if the program were printed 50 lines per page. The printout would occupy a volume of about 6.5 cubic feet. Biological entities such as human beings are of similar volume and they are far more complex than computer software, but there are few, if any, human - made artifacts of comparable size that are as complex as software.
Brooks says, “ Software entities are more complex for their size [emphasis added] than perhaps any other human construct, because no two parts are alike (at least
above the statement level). ” It is diffi cult to visualize the size of a software program because software has no physical attributes; however, if one were to print a one - million line program the stack of paper would be about 10 feet (roughly 3 meters) high if the program were printed 50 lines per page. The printout would occupy a volume of about 6.5 cubic feet. Biological entities such as human beings are of similar volume and they are far more complex than computer software, but there are few, if any, human - made artifacts of comparable size that are as complex as software.
How is the java memory pool divided?
Heap memory
The heap memory is the runtime data area from which the Java VM allocates memory for all class instances and arrays. The heap may be of a fixed or variable size. The garbage collector is an automatic memory management system that reclaims heap memory for objects.
- Eden Space: The pool from which memory is initially allocated for most objects.
- Survivor Space: The pool containing objects that have survived the garbage collection of the Eden space.
- Tenured Generation: The pool containing objects that have existed for some time in the survivor space.
Non-heap memory
Non-heap memory includes a method area shared among all threads and memory required for the internal processing or optimization for the Java VM. It stores per-class structures such as a runtime constant pool, field and method data, and the code for methods and constructors. The method area is logically part of the heap but, depending on the implementation, a Java VM may not garbage collect or compact it. Like the heap memory, the method area may be of a fixed or variable size. The memory for the method area does not need to be contiguous.
- Permanent Generation: The pool containing all the reflective data of the virtual machine itself, such as class and method objects. With Java VMs that use class data sharing, this generation is divided into read-only and read-write areas.
- Code Cache: The HotSpot Java VM also includes a code cache, containing memory that is used for compilation and storage of native code.
Monday, June 23, 2014
Sheep
Harmlessly passing your time in the grassland away
Only dimly aware of a certain unease in the air
You better watch out,
There may be dogs about
I've looked over Jordan, and I have seen.
Things are not what they seem
Only dimly aware of a certain unease in the air
You better watch out,
There may be dogs about
I've looked over Jordan, and I have seen.
Things are not what they seem
Saturday, June 14, 2014
Friday, June 13, 2014
Thursday, June 12, 2014

Sunday, June 01, 2014
Friday, May 30, 2014

Saturday, May 24, 2014
Thursday, May 22, 2014
Sunday, May 18, 2014
Saturday, May 10, 2014
Thursday, May 01, 2014
Sunday, April 27, 2014

Monday, April 21, 2014

Saturday, April 19, 2014

Friday, April 18, 2014
Sunday, April 13, 2014
Saturday, April 12, 2014
Everyday Enterprise Architecture
Whatever we do, however we approach it, and whichever part of the organisation we work in, all of enterprise-architecture comes down to one single, simple idea:

"Things work better when they work together, with clarity, with elegance, on purpose."Enterprise-architects are responsible to the organisation to make that happen: the underlying aim of every item of architecture-work in the enterprise is to make things work better for everyone.
Sunday, April 06, 2014
Aquele que está só é inocenteAquele que está só é inocente
"Um dos fatores do sofrimento é o extraordinário isolamento do homem. Você pode ter companheiros, pode ter deuses, pode ter muito conhecimento, você pode ser extraordinariamente ativo socialmente, fazer fofocas intermináveis sobre política – e muitos políticos fazem fofoca de qualquer jeito – e este isolamento permanece. Assim, o homem procura descobrir significado na vida e inventa um significado, um propósito. Mas o isolamento ainda permanece. Então, pode você olhar para ele sem comparação, apenas vê-lo como ele é, sem tentar correr dele, sem tentar encobri-lo, ou fugir dele? Então você verá que o isolamento se torna algo inteiramente diferente. Nós não estamos sós. Somos o resultado de milhares de influências, milhares de condicionamentos, heranças psicológicas, propaganda, cultura. Não estamos sós e, por isso, somos seres humanos de segunda mão. Quando se está só, totalmente só, não pertencendo a nenhuma família, embora você possa ter uma, nem pertencendo a qualquer nação, qualquer cultura, a qualquer compromisso particular, existe o sentimento de ser um estranho, estranho a toda forma de pensamento, ação, família, nação. E apenas aquele que está completamente só é inocente. É esta inocência que liberta a mente do sofrimento." -
Krishnamurti, J. Krishnamurti, The Book of Life

Krishnamurti, J. Krishnamurti, The Book of Life
Monday, March 31, 2014
Five Aspects of Service Design
There are five aspects of design that need to be considered:

- The design of the services, including all of the functional requirements, resources and capabilities needed and agreed
- The design of service management systems and tools, especially the Service Portfolio, for the management and control of services through their lifecycle
- The design of the technology architectures and management systems required to provide the services
- The design of the processes needed to design, transition, operate and improve the services, the architectures and the processes themselves
- The design of the measurement methods and metrics of the services, the architectures and their constituent components and the processes.
Business Value
With good Service Design it will be possible to deliver quality, cost-effective services and to ensure that the
business requirements are being met. The following benefits are as a result of good Service Design practice:
business requirements are being met. The following benefits are as a result of good Service Design practice:
- Reduced total cost of ownership (TCO): cost of ownership can only be minimized if all aspects of services, processes and technology are designed properly and implemented against the design
- Improved quality of service: both service and operational quality will be enhanced
- Improved consistency of service: as services are designed within the corporate strategy, architectures and constraints
- Easier implementation of new or changed services: as there is integrated and full Service Design, and the production of comprehensives Service Design Packages
- Improved service alignment: involvement from the conception of the service ensuring that new or changed services match business needs, with services designed to meet Service Level Requirements
- More effective service performance: with incorporation and recognition of Capacity, Financial, Availability and IT Service Continuity plans
- Improved IT governance: assists with the implementation and communication of a set of controls for effective governance of IT
- More effective service management and IT processes: processes will be designed with optimal quality and cost-effectiveness
- Improved information and decision-making: more comprehensive and effective measurements and metrics will enable better decision-making and continual improvement of service management practices in the design stage of the Service Lifecycle.
Saturday, March 29, 2014



Message Bus
An enterprise contains several existing systems that must be able to share data and operate in a unified manner in response to a set of common business requests.
Scenario One (problem)

Solution

Scenario Two (solution)

Scenario One (problem)
Solution
Scenario Two (solution)
Messaging Systems
Messaging makes applications loosely coupled by communicating asynchronously, which also makes the communication more reliable because the two applications do not have to be running at the same time. Messaging makes the messaging system responsible for transferring data from one application to another, so the applications can focus on what data they need to share but not worry so much about how to share it.
Channels — Messaging applications transmit data through a Message Channel, a virtual pipe that connects a sender to a receiver. A newly installed messaging system doesn’t contain any channels; you must determine how your applications need to communicate and then create the channels to facilitate it.
Messages — A Message is an atomic packet of data that can be transmitted on a channel. Thus to transmit data, an application must break the data into one or more packets, wrap each packet as a message, and then send the message on a channel. Likewise, a receiver application receives a message and must extract the data from the message to process it. The message system will try repeatedly to deliver the message (e.g., transmit it from the sender to the receiver) until it succeeds.
Multi-step delivery (or pipes & filters)— In the simplest case, the message system delivers a message directly from the sender’s computer to the receiver’s computer. However, actions often need to be performed on the message after it is sent by its original sender but before it is received by its final receiver. For example, the message may have to be validated or transformed because the receiver expects a different message format than the sender. A Pipes and Filters architecture describes how multiple processing steps can be chained together using channels.
Routing — In a large enterprise with numerous applications and channels to connect them, a message may have to go through several channels to reach its final destination. The route a message must follow may be so complex that the original sender does not know what channel will get the message to the final receiver. Instead, the original sender sends the message to a Message Router, an application component and filter in the pipes-and-filters architecture, which will determine how to navigate the channel topology and direct the message to the final receiver, or at least to the next router.
Transformation — Various applications may not agree on the format for the same conceptual data; the sender formats the message one way, yet the receiver expects it to be formatted another way. To reconcile this, the message must go through an intermediate filter, a Message Translator, that converts the message from one format to another.
Endpoints — An application does not have some built-in capability to interface with a messaging system. Rather, it must contain a layer of code that knows both how the application works and how the messaging system works, bridging the two so that they work together. This bridge code is a set of coordinated Message Endpoints that enable the application to send and receive messages.
Channels — Messaging applications transmit data through a Message Channel, a virtual pipe that connects a sender to a receiver. A newly installed messaging system doesn’t contain any channels; you must determine how your applications need to communicate and then create the channels to facilitate it.
Messages — A Message is an atomic packet of data that can be transmitted on a channel. Thus to transmit data, an application must break the data into one or more packets, wrap each packet as a message, and then send the message on a channel. Likewise, a receiver application receives a message and must extract the data from the message to process it. The message system will try repeatedly to deliver the message (e.g., transmit it from the sender to the receiver) until it succeeds.
Multi-step delivery (or pipes & filters)— In the simplest case, the message system delivers a message directly from the sender’s computer to the receiver’s computer. However, actions often need to be performed on the message after it is sent by its original sender but before it is received by its final receiver. For example, the message may have to be validated or transformed because the receiver expects a different message format than the sender. A Pipes and Filters architecture describes how multiple processing steps can be chained together using channels.
Routing — In a large enterprise with numerous applications and channels to connect them, a message may have to go through several channels to reach its final destination. The route a message must follow may be so complex that the original sender does not know what channel will get the message to the final receiver. Instead, the original sender sends the message to a Message Router, an application component and filter in the pipes-and-filters architecture, which will determine how to navigate the channel topology and direct the message to the final receiver, or at least to the next router.
Transformation — Various applications may not agree on the format for the same conceptual data; the sender formats the message one way, yet the receiver expects it to be formatted another way. To reconcile this, the message must go through an intermediate filter, a Message Translator, that converts the message from one format to another.
Endpoints — An application does not have some built-in capability to interface with a messaging system. Rather, it must contain a layer of code that knows both how the application works and how the messaging system works, bridging the two so that they work together. This bridge code is a set of coordinated Message Endpoints that enable the application to send and receive messages.
Message Endpoint
The application and the messaging system are two separate sets of software. The application provides functionally for some type of user, whereas the messaging system manages messaging channels for transmitting messages for communication. Even if the messaging system is incorporated as a fundamental part of the application, it is still a separate, specialized provider of functionality much like a database management system or a web server. Because the application and the messaging system are separate, they must have a way to connect and work together.


Connect an application to a messaging channel using a Message Endpoint, a client of the messaging system that the application can then use to send or receive messages.
Message Translator
Use a special filter, a Message Translator, between other filters or applications to translate one data format into another.

Chaining Transformations

Chaining Transformations
Message Router
Multiple processing steps in a Pipes and Filters chain are connected by Message Channels. A Message Channel decouples the sender and the receiver of a Message. This means that multiple applications can publish Messages to a Message Channel. As a result, a message channel can contain messages from different sources that may have to be treated differently based on the type of the message or other criteria. You could create a separate Message Channel for each message type (a concept explained in more detail later as a Datatype Channel) and connect each channel to the required processing steps for that message type. However, this would require the message
originators to be aware of the selection criteria for different processing steps, so that they can publish the message to the correct channel. It could also lead to an explosion of the number of Message Channels. Also, the decision on which steps the message undergoes may not just depend on the origin of the message. For example, we could imagine a situation where the destination of
a message changes by the number of messages that have passed through the channel so far. No single originator would know this number and would therefore be unable to send the message to the correct channel.
Insert a special filter, a Message Router, which consumes a Message from one Message Channel and republishes it to a different Message Channel channel depending on a set of conditions.

originators to be aware of the selection criteria for different processing steps, so that they can publish the message to the correct channel. It could also lead to an explosion of the number of Message Channels. Also, the decision on which steps the message undergoes may not just depend on the origin of the message. For example, we could imagine a situation where the destination of
a message changes by the number of messages that have passed through the channel so far. No single originator would know this number and would therefore be unable to send the message to the correct channel.
Insert a special filter, a Message Router, which consumes a Message from one Message Channel and republishes it to a different Message Channel channel depending on a set of conditions.
Parallel Processing
However, the overall system throughput is limited by the slowest process in the chain. To improve throughput we can deploy multiple parallel instances of that process to improve throughput. In this scenario, a Point-to-Point Channel with Competing Consumers is needed to guarantee that each message on the channel is consumed by exactly one of N available processors. This allows us to speed up the most time-intensive process and improve overall throughput. However, this configuration can cause messages to be processed out of order. If the sequence of messages is critical, we can only run one instance of each component or use a Resequencer.

Pipeline Processing
Connecting components with asynchronous Message Channels allows each unit in the chain to operate in its own thread or its own process. When a unit has completed processing one message it can send the message to the output channel and immediately start processing another message.

Pipes & Filters
Use the Pipes and Filters architectural style to divide a larger processing task into a sequence of smaller, independent processing steps (Filters) that are connected by channels (Pipes).

Message
Package the information into a Message, a data record that the messaging system can transmit
through a message channel.

A message consists of two basic parts:
through a message channel.
A message consists of two basic parts:
- Header – Information used by the messaging system that describes the data being transmitted, its origin, its destination, and so on.
- 2. Body – The data being transmitted; generally ignored by the messaging system and simply transmitted as-is.
Message Channel
Once a group of applications have a messaging system available, it's tempting to think that any application can communicate with any other application any time desired.

Saturday, March 22, 2014
Integration Styles - Application Integration Options
File Transfer — Have each application produce files of shared data for others to consume, and consume files that others have produced.

Shared Database — Have the applications store the data they wish to share in a common database.

Remote Procedure Invocation — Have each application expose some of its procedures so that they can be invoked remotely, and have applications invoke those to run behavior and exchange data.

Messaging — Have each application connect to a common messaging system, and exchange data and invoke behavior using messages.

Decision Criteria
Application coupling — Even integrated applications should minimize their dependencies on each other so that each can evolve without causing problems for the others. Tightly coupled applications make numerous assumptions about how the other applications work; when the applications change and break those assumptions, the integration breaks. The interface for integrating applications should be specific enough to implement useful functionality, but general enough to allow that implementation to change as needed.
Integration simplicity — When integrating an application into an enterprise, developers should strive to minimize changing the application and minimize the amount of integration code needed. Yet changes and new code will usually be necessary to provide good integration functionality, and the approaches with the least impact on the application may not provide the best integration into the enterprise.
Integration technology — Different integration techniques require varying amounts of specialized software and hardware. These special tools can be expensive, can lead to vendor lock-in, and increase the burden on developers to understand how to use the tools to integrate applications.
Data format — Integrated applications must agree on the format of the data they exchange, or must have an intermediate traslator to unify applications that insist on different data formats. A related issue is data format evolution and extensibility—how the format can change over time and how that will affect the applications.
Data timeliness — Integration should minimize the length of time between when one application decides to share some data and other applications have that data. Data should be exchanged frequently in small chunks, rather than waiting to exchange a large set of unrelated items. Applications should be informed as soon as shared data is ready for consumption. Latency in data sharing has to be factored into the integration design; the longer sharing can take, the more opportunity for shared data to become stale, and the more complex integration becomes.
Data or functionality — Integrated applications may not want to simply share data, they may wish to share functionality such that each application can invoke the functionality in the others. Invoking functionality remotely can be difficult to achieve, and even though it may seem the same as invoking local functionality, it works quite differently, with significant consequences for how well the integration works.
Asynchronicity — Computer processing is typically synchronous, such that a procedure waits while its subprocedure executes. It’s a given that the subprocedure is available when the procedure wants to invoke it. However, a procedure may not want to wait for the subprocedure to execute; it may want to invoke the subprocedure asynchronously, starting the subprocedure but then letting it execute in the background. This is especially true of integrated applications, where the remote application may not be running or the network may be unavailable—the source application may wish to simply make shared data available or log a request for a subprocedure call, but then go on to other work confident that the remote application will act
sometime later.
Shared Database — Have the applications store the data they wish to share in a common database.
Remote Procedure Invocation — Have each application expose some of its procedures so that they can be invoked remotely, and have applications invoke those to run behavior and exchange data.
Messaging — Have each application connect to a common messaging system, and exchange data and invoke behavior using messages.
Decision Criteria
Application coupling — Even integrated applications should minimize their dependencies on each other so that each can evolve without causing problems for the others. Tightly coupled applications make numerous assumptions about how the other applications work; when the applications change and break those assumptions, the integration breaks. The interface for integrating applications should be specific enough to implement useful functionality, but general enough to allow that implementation to change as needed.
Integration simplicity — When integrating an application into an enterprise, developers should strive to minimize changing the application and minimize the amount of integration code needed. Yet changes and new code will usually be necessary to provide good integration functionality, and the approaches with the least impact on the application may not provide the best integration into the enterprise.
Integration technology — Different integration techniques require varying amounts of specialized software and hardware. These special tools can be expensive, can lead to vendor lock-in, and increase the burden on developers to understand how to use the tools to integrate applications.
Data format — Integrated applications must agree on the format of the data they exchange, or must have an intermediate traslator to unify applications that insist on different data formats. A related issue is data format evolution and extensibility—how the format can change over time and how that will affect the applications.
Data timeliness — Integration should minimize the length of time between when one application decides to share some data and other applications have that data. Data should be exchanged frequently in small chunks, rather than waiting to exchange a large set of unrelated items. Applications should be informed as soon as shared data is ready for consumption. Latency in data sharing has to be factored into the integration design; the longer sharing can take, the more opportunity for shared data to become stale, and the more complex integration becomes.
Data or functionality — Integrated applications may not want to simply share data, they may wish to share functionality such that each application can invoke the functionality in the others. Invoking functionality remotely can be difficult to achieve, and even though it may seem the same as invoking local functionality, it works quite differently, with significant consequences for how well the integration works.
Asynchronicity — Computer processing is typically synchronous, such that a procedure waits while its subprocedure executes. It’s a given that the subprocedure is available when the procedure wants to invoke it. However, a procedure may not want to wait for the subprocedure to execute; it may want to invoke the subprocedure asynchronously, starting the subprocedure but then letting it execute in the background. This is especially true of integrated applications, where the remote application may not be running or the network may be unavailable—the source application may wish to simply make shared data available or log a request for a subprocedure call, but then go on to other work confident that the remote application will act
sometime later.

Thinking Asynchronously
Messaging is an asynchronous technology, which enables delivery to be retried until it succeeds. In contrast, most applications use synchronous function calls; for example: a procedure calling a sub-procedure, one method calling another method, or one procedure invoking another remotely through a remote procedure call (RPC) (such as CORBA and DCOM). Synchronous calls imply that the calling process is halted while the sub-process is executing a function. Even in an RPC scenario, where the called sub-procedure executes in a different process, the caller blocks until the sub-procedure returns control (and the results) to the caller. When using asynchronous messaging, the caller uses a send and forget approach that allows it to continue to execute after it sends the message. As a result, the calling procedure continues to run while the sub-procedure is being invoked.

Subscribe to:
Posts (Atom)