
As
novas demandas dos negócios começam a exigir sistemas 24x7, disponíveis
sete dias por semana, vinte e quatro horas por dia. O tempo que estes
ssitemas podem ficar fora do ar são cuidadosamente definidos e
normalmente utilizam-se métricas que regem os contratos entre as áreas
fins e a área de TI.
Deve ficar claro que o negócio define o nível de disponibilidade necessária pois quanto maior a disponibilidade requerida maior o investimento em infra-estrutura.
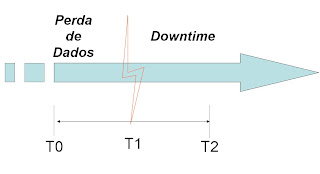
A figura abaixo representa um acidente no tempo T1 ocorrido em um determinado sistema. O tempo decorrido entre T1 e T2 é o tempo de downtime. O tempo T0 é o tempo de perda de dados durante o downtime. Quanto menor o tempo de downtime e menor o tempo de perda de dados maior a disponibilidade do sistema e maior o investimento em tecnologias que permitem a recuperação do site.
Deve ficar claro que o negócio define o nível de disponibilidade necessária pois quanto maior a disponibilidade requerida maior o investimento em infra-estrutura.
A figura abaixo representa um acidente no tempo T1 ocorrido em um determinado sistema. O tempo decorrido entre T1 e T2 é o tempo de downtime. O tempo T0 é o tempo de perda de dados durante o downtime. Quanto menor o tempo de downtime e menor o tempo de perda de dados maior a disponibilidade do sistema e maior o investimento em tecnologias que permitem a recuperação do site.
 A
Alta disponibilidade significa que o serviço de TI está continuamente
disponível para o cliente havendo pouco downtime e recuperação rápida. A
alta disponibilidade (HA) e a recuperação a desastres (DR) devem ser
pensadas como um continuum e acontecem em várias camadas , onde cada
camada propicia os níveis de disponibilidade adequado para a camada
superior.
A
Alta disponibilidade significa que o serviço de TI está continuamente
disponível para o cliente havendo pouco downtime e recuperação rápida. A
alta disponibilidade (HA) e a recuperação a desastres (DR) devem ser
pensadas como um continuum e acontecem em várias camadas , onde cada
camada propicia os níveis de disponibilidade adequado para a camada
superior.
A
alta disponibilidade hoje é considerada o principal SLA de qualquer
instalação de DATACENTER. Para se obter um nível de serviço adequado é
necessário que os componentes de toda a solução contribuam para a
obtenção deste nível de serviço.
Quase todo usuário de sistema quando interrogado sobre qual o SLA requerido sempre diz que é 100%, mas sabe-se que para muitas aplicações um SLA menor é mais do que suficiente e economico (ver artigo Porque ILM ? neste blog ). A disponibilidade que é percebida pelo usuário depende da quantidade de indisponibilidades, da duração da indisponibilidade e da quantidade de usuários afetados,A disponibilidade (ou a alta disponibilidade) de um sistema é calculada da seguinte forma:
Quase todo usuário de sistema quando interrogado sobre qual o SLA requerido sempre diz que é 100%, mas sabe-se que para muitas aplicações um SLA menor é mais do que suficiente e economico (ver artigo Porque ILM ? neste blog ). A disponibilidade que é percebida pelo usuário depende da quantidade de indisponibilidades, da duração da indisponibilidade e da quantidade de usuários afetados,A disponibilidade (ou a alta disponibilidade) de um sistema é calculada da seguinte forma:
 Onde
A é o grau de disponibilidade expresso em porcentagem, MTBF é o mean
time between failures e o MTTR é o maximum time to repair. Se um sistema
tem MTBF de 100.000 horas (mais que 11 anos) e o MTTR é de 1 hora , o
disponibilidade (A) é de 99.9999 %. Ou seja em 11 anos teremos neste caso 6 minutos de downtime.
Onde
A é o grau de disponibilidade expresso em porcentagem, MTBF é o mean
time between failures e o MTTR é o maximum time to repair. Se um sistema
tem MTBF de 100.000 horas (mais que 11 anos) e o MTTR é de 1 hora , o
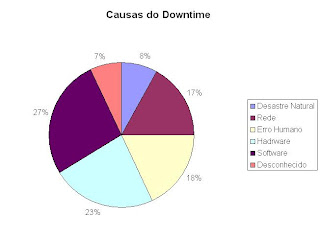
disponibilidade (A) é de 99.9999 %. Ou seja em 11 anos teremos neste caso 6 minutos de downtime.Há uma tendencia que o downtime (tempo que o sistema esta fora do ar) considerado por organizações que atuam 24x7 inclua a indisponibilidade planejada e a indisponibilidade não planejada. O downtime não planejado tem sua fonte principal na falha do software, segundo pesquisa realizada pelo Gartner/Dataquest e mostrada o gráfico abaixo.
A alta disponibilidade alcançada é indicada por métricas como mostrado na tabela abaixo.
É muito comum associar o nível de alta disponibilidade a percentagem de uptime que o sistema permite . Sistemas com cinco noves (99.999%) podem parar cinco minutos e 15 segundos ao longo do ano considerando inclusive as paradas programadas.
É muito comum associar o nível de alta disponibilidade a percentagem de uptime que o sistema permite . Sistemas com cinco noves (99.999%) podem parar cinco minutos e 15 segundos ao longo do ano considerando inclusive as paradas programadas.

Vejamos
o exemplo de um serviço fim a fim baseado em uma aplicação
client/server prometido por um fornecedor com 99.99% de disponibilidade.
Na verdade considerando todo o sistema é muito dificil ter um SLA desta
ordem. Vejamos o processo de realizar uma consulta a esta aplicação
client/server realizada por um usuário (na sua estação de trabalho - o
client). Entre os dois estão a estação do cliente, a rede LAN da
organização, a rede WAN, os servidores, a aplicação e finalmente o storage. Não estamos considerando alguns componentes para facilitar (firewall, switches, etc.)
 Para simplificar vamos considerar que existem sete componentes entre o client e o storage.
Se cada componente tiver 99.99% e assumirmos que as falhas não
acontecem ao mesmo tempo , o SLA final da cadeia é de 99.93%
(0.9999*0.9999*0.9999*0.9999*0.9999*0.9999*0.9999) que não representa 52
minutos parados no ano mais sim 6 horas ! That is the question !
Para simplificar vamos considerar que existem sete componentes entre o client e o storage.
Se cada componente tiver 99.99% e assumirmos que as falhas não
acontecem ao mesmo tempo , o SLA final da cadeia é de 99.93%
(0.9999*0.9999*0.9999*0.9999*0.9999*0.9999*0.9999) que não representa 52
minutos parados no ano mais sim 6 horas ! That is the question !Pois bem ! Este papo de sistemas fim a fim com cinco noves que teoricamente ficariam trinta e dois segundos fora do ar por ano é balela ! Outro aspecto importante é que o simples fato de um dos componentes da rede ter um SLA menor dispenca o SLA médio final. É só fazer a conta.
Algumas regras importantes:
1 - Investir em um único componente tem pouco impacto no SLA total;
1.00*.995*.995*.995=98.5% (sai de 99.5% para 98.5%
2- Um componente pouco confiável reduz consideravelmente o SLA total;
0.95*.995*.995*.995=98.5% (sai de 99.5% para 93,6%)
3- Melhor cuidar da cadeia de SLA inteira
0.9975*0.9975*0.9975*0.9975=99%
Referência:
[1]Marcus, Evan & Stern, Hal. Blueprints for High Availability, Second Edition, 2003.
[2]Jorge Luís Cordenonsi, Gerenciamento da Disponibilidade de TI, material disponível na Internet.
No comments:
Post a Comment