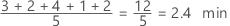Software is an instrument created to help us deal with the complexities of our modern life. Software is just the means to an end, and usually that end is something very practical and real. Software development is most often applied to automating processes that exist in the real world, or providing solutions to real business problems; The business processes being automated or real world problems that the software is the domain of the software. We must understand from the beginning that software is originated from and deeply related to this domain.
Chances are that you have developed a layered (web) application in the past. You might even be doing it in your current project right now (actually, I am).
Figure 1 - A conventional web application architecture consists of a web layer, a domain layer, and a persistence layer.
Figure 1 shows a high-level view of the very common three-layer architecture. We have a web layer that receives requests and routes them to a service in the domain or “business” layer. The service does some business magic and calls components from the persistence layer to query for or modify the current state of our domain entities.
So, what’s wrong with layers? In my experience a layered architecture has too many open flanks that allow bad habits to creep in and make the software increasingly harder to change over time. In the following sections, I’ll tell you why.
It Promotes Database-Driven Design
By its very definition, the foundation of a conventional layered architecture is the database. The web layer depends on the domain layer which in turn depends on the persistence layer and thus the database.
Figure 2 - Using the database entities in the domain layer leads to strong coupling with the persistence layer.
Usually, we have ORM-managed entities as part of the persistence layer as shown in figure 2. Since layers may access the layers below them, the domain layer is allowed to access those entities. And if it’s allowed to use them, they will be used.
This creates a strong coupling between the persistence layer and the domain layer. Our services use the persistence model as their business model and not only have to deal with the domain logic, but also with eager vs. lazy loading, database transactions, flushing caches and similar housekeeping tasks.
The persistence code is virtually fused into the domain code and thus it’s hard to change one without the other. That’s the opposite of being flexible and keeping options open, which should be the goal of our architecture.
It’s Prone to Shortcuts
In a conventional layered architecture, the only global rule is that from a certain layer, we can only access components in the same layer or a layer below. There may be other rules that a development team has agreed upon and some of them might even be enforced by tooling, but the layered architecture style itself does not impose those rules on us. So, if we need access to a certain component in a layer above ours, we can just push the component down a layer and we’re allowed to access it. Problem solved.
Doing this once may be OK. But doing it once opens the door for doing it a second time. And if someone else was allowed to do it, so am I, right? I’m not saying that as developers, we take such shortcuts lightly. But if there is an option to do something, someone will do it, especially in combination with a looming deadline. And if something has been done before, the threshold for someone to do it again will lower drastically. This is a psychological effect called the “Broken Windows Theory”.
Figure 3 - Since we may access everything in the persistence layer, it tends to grow fat over time.
The persistence layer (or in more generic terms: the bottom-most layer) will grow fat as we push components down through the layers. Perfect candidates for this are helper or utility components since they don’t seem to belong to any specific layer.
So, if we want to disable the “shortcut mode” for our architecture, layers are not the best option, at least not without enforcing some kind of additional architecture rules. And with “enforce” I don’t mean a senior developer doing code reviews but rules that make the build fail when they’re broken.
It Grows Hard to Test
A common evolution within a layered architecture is that layers are being skipped. We access the persistence layer directly from the web layer, since we’re only manipulating a single field of an entity and for that we need not bother the domain layer, right?
Figure 4 - Skipping the domain layer tends to scatter domain logic across the codebase.
Again, this feels OK the first couple of times, but it has two drawbacks if it happens often (and it will, once someone has done the first step). First, we’re implementing domain logic in the web layer, even if it’s only manipulating a single field.
What if the use case expands in the future? We’re most likely going to add more domain logic to the web layer, mixing responsibilities and spreading essential domain logic all over the application. Second, in the tests of our web layer, we not only have to mock away the domain layer, but also
the persistence layer. This adds complexity to the unit test. And a complex test setup is the first step towards no tests at all because we don’t have time for them.
As the web component grows over time, it may accumulate a lot of dependencies to different persistence components, adding to the test’s complexity. At some point, it takes more time for us to understand and mock away the dependencies than to actually write test code.
It Hides the Use Cases
As developers, we like to create new code that implements shiny new use cases. But we usually spend such more time changing existing code than we do creating new code. This is not only true for those readed legacy projects in which we’re working on a decades-old codebase but also for a hot new reenfield project after the initial use cases have been implemented.
Since we’re so often searching for the right place to add or change functionality, our architecture should help us to quickly navigate the codebase. How is a layered architecture holding up in this regard?
As already discussed above, in a layered architecture it easily happens that domain logic is scattered throughout the layers. It may exist in the web layer if we’re skipping the domain logic for an “easy” use case. And it may exist in the persistence layer if we have pushed a certain component down so it can be accessed from both the domain and the persistence layer. This already makes finding the right spot to add new functionality hard.
But there’s more. A layered architecture does not impose rules on the “width” of domain services. Over time, this often leads to very broad services that serve multiple use cases.
Figure 5 - “Broad” services make it hard to find a certain use case within the codebase.
A broad service has many dependencies to the persistence layer and many components in the web layer depend on it. This not only makes the service hard to test, but also makes it hard for us to find the service responsible for the use case we want to work on.
How much easier would it be if we had highly-specialized narrow domain services that each serve a single use case? Instead of searching for the user registration use case in the UserService, we would just open up the RegisterUserService and start working.
It Makes Parallel Work Difficult
Management usually expects us to be done with building the software they sponsor at a certain date. Actually, they even expect us to be done within a certain budget as well, but let’s not complicate things here.
Aside from the fact that I have never seen “done” software in my career as a software developer, to be done by a certain date usually implies that we have to work in parallel.
Probably you know this famous conclusion from “The Mythical Man-Month”, even if you haven’t read the book:
Adding manpower to a late software project makes it later.
they’re working on a very large application where they can split up in sub teams and work on separate parts of the software, it may work, but in most contexts they would stand on each other’s feet.
But at a healthy scale, we can certainly expect to be faster with more people on the project. And management is right to expect that of us. To meet this expectation, our architecture must support parallel work. This is not easy. And a layered architecture doesn’t really help us here. Imagine we’re adding a new use case to our application. We have three developers available. One can add the needed features to the web layer, one to the domain layer and the third to the persistence layer, right?
Well, it usually doesn’t work that way in a layered architecture. Since everything builds on top of the persistence layer, the persistence layer must be developed first. Then comes the domain layer and finally the web layer. So only one developer can work on the feature at the same time!
Ah, but the developers can define interfaces first, you say, and then each developer can work against these interfaces without having to wait for the actual implementation. Sure, this is possible, but only if we’re not doing Database-Driven Design as discussed above, where our persistence logic is so mixed up with our domain logic that we just cannot work on each aspect separately.
If we have broad services in our codebase, it may even be hard to work on different features in parallel. Working on different use cases will cause the same service to be edited in parallel which leads to merge conflicts and potentially regressions.