
Sunday, March 28, 2021

Cosmic Calendar

|
Date |
Billion Years |
Event |
|
Jan 1st |
13.8 |
Big Bang |
|
March 15st |
11.0 |
The Milky
Way Galaxy is formed |
|
August 31st |
4.57 |
the sun is
formed (Planet and satellite shortly thereafter) |
|
Sept 16st |
4.0 |
The oldest
known rock on earth |
|
Sept 21st |
3.8 |
first life (prokaryotes) |
|
Oct 12st |
3 |
photosynthesis |
|
Oct 29st |
2.4 |
atmospheric oxygenation |
|
Nov 9st |
2 |
complex cells (eukaryotes) |
|
Des 5st |
1 |
The first multicell life |
|
Des 14st |
0.67 |
simple animals |
|
Des 14st |
0.55 |
ancestral insects (arthropods) |
|
Des 18st |
0.5 |
fish and amphibious proto |
|
Des 20st |
0.45 |
Land plants |
|
Des 21st |
0.4 |
insects and seeds |
|
Des 22st |
0.36 |
amphibians |
|
Des 23 st |
0.3 |
Reptile |
|
Des 26st |
0.2 |
mammals |
|
Des 27st |
0.15 |
Bird |
|
Des 28st |
0.13 |
Flower |
|
Des 30 at 06:24 |
0.065 |
The
lime-paleogen extinction event, a non-bird dinosaur extinct |
Thursday, March 25, 2021
CAP Theorem and Distributed Database Management Systems
In the past, when we wanted to store more data or increase our processing power, the common option was to scale vertically (get more powerful machines) or further optimize the existing code base. However, with the advances in parallel processing and distributed systems, it is more common to expand horizontally, or have more machines to do the same task in parallel. We can already see a bunch of data manipulation tools in the Apache project like Spark, Hadoop, Kafka, Zookeeper and Storm. However, in order to effectively pick the tool of choice, a basic idea of CAP Theorem is necessary. CAP Theorem is a concept that a distributed database system can only have 2 of the 3: Consistency, Availability and Partition Tolerance.
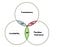

CAP Theorem is very important in the Big Data world, especially when we need to make trade off’s between the three, based on our unique use case. On this blog, I will try to explain each of these concepts and the reasons for the trade off. I will avoid using specific examples as DBMS are rapidly evolving.
Partition Tolerance
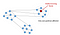

This condition states that the system continues to run, despite the number of messages being delayed by the network between nodes. A system that is partition-tolerant can sustain any amount of network failure that doesn’t result in a failure of the entire network. Data records are sufficiently replicated across combinations of nodes and networks to keep the system up through intermittent outages. When dealing with modern distributed systems, Partition Tolerance is not an option. It’s a necessity. Hence, we have to trade between Consistency and Availability.
High Consistency
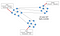

This condition states that all nodes see the same data at the same time. Simply put, performing a read operation will return the value of the most recent write operation causing all nodes to return the same data. A system has consistency if a transaction starts with the system in a consistent state, and ends with the system in a consistent state. In this model, a system can (and does) shift into an inconsistent state during a transaction, but the entire transaction gets rolled back if there is an error during any stage in the process. In the image, we have 2 different records (“Bulbasaur” and “Pikachu”) at different timestamps. The output on the third partition is “Pikachu”, the latest input. However, the nodes will need time to update and will not be Available on the network as often.
High Availability
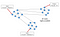

This condition states that every request gets a response on success/failure. Achieving availability in a distributed system requires that the system remains operational 100% of the time. Every client gets a response, regardless of the state of any individual node in the system. This metric is trivial to measure: either you can submit read/write commands, or you cannot. Hence, the databases are time independent as the nodes need to be available online at all times. This means that, unlike the previous example, we do not know if “Pikachu” or “Bulbasaur” was added first. The output could be either one. Hence why, high availability isn’t feasible when analyzing streaming data at high frequency.
Conclusion
Distributed systems allow us to achieve a level of computing power and availability that were simply not available in the past. Our systems have higher performance, lower latency, and near 100% up-time in data centers that span the entire globe. Best of all, the systems of today are run on commodity hardware that is easily obtainable and configurable at affordable costs. However, there is a price. Distributed systems are more complex than their single-network counterparts. Understanding the complexity incurred in distributed systems, making the appropriate trade-offs for the task at hand (CAP), and selecting the right tool for the job is necessary with horizontal scaling.
https://towardsdatascience.com/cap-theorem-and-distributed-database-management-systems-5c2be977950e
Sunday, March 21, 2021
Derivative Rules
| Common Functions | Function | Derivative |
|---|---|---|
| Constant | c | 0 |
| Line | x | 1 |
| ax | a | |
| Square | x2 | 2x |
| Square Root | √x | (½)x-½ |
| Exponential | ex | ex |
| ax | ln(a) ax | |
| Logarithms | ln(x) | 1/x |
| loga(x) | 1 / (x ln(a)) | |
| Trigonometry (x is in radians) | sin(x) | cos(x) |
| cos(x) | −sin(x) | |
| tan(x) | sec2(x) | |
| Inverse Trigonometry | sin-1(x) | 1/√(1−x2) |
| cos-1(x) | −1/√(1−x2) | |
| tan-1(x) | 1/(1+x2) | |
| Rules | Function | Derivative |
| Multiplication by constant | cf | cf’ |
| Power Rule | xn | nxn−1 |
| Sum Rule | f + g | f’ + g’ |
| Difference Rule | f - g | f’ − g’ |
| Product Rule | fg | f g’ + f’ g |
| Quotient Rule | f/g | (f’ g − g’ f )/g2 |
| Reciprocal Rule | 1/f | −f’/f2 |
| Chain Rule (as "Composition of Functions") | f º g | (f’ º g) × g’ |
| Chain Rule (using ’ ) | f(g(x)) | f’(g(x))g’(x) |
| Chain Rule (using ddx ) | dydx = dydududx | |
Wednesday, March 17, 2021
The statistical machine learning framework.

The Data Generating Process (DGP) generates observable training data from the unobservable environmental probability distribution P(e). The learning machine observes the training data and uses its beliefs about the structure of the environmental probability distribution in order to construct a bestapproximating distribution P of the environmental distribution P(e). The resulting bestapproximating distribution of the environmental probability distribution supports decisions and behaviors by the learning machine for the purpose of improving its success when interacting with an environment characterized by uncertainty.
Os perigos da antropomorfização de empresas na Internet
Uma personalidade antropomorfizada engana o seu cérebro e faz com que você a encaixe num sistema de pensamento (schema) pré estabelecido. Ela se mescla ao cenário do seu dia a dia e passa a fazer parte do seu pensamento cotidiano sem você questionar.
Então, não, o meme não vai te fazer comprar no iFood. Mas a questão não é a efetividade do anúncio em si (anúncio, porque o tweet engraçado é um anúncio); a questão é a completa onipresença das empresas em todos os aspectos e momentos da nossa vida e o quão complexa a mecanização de anunciar se tornou.
https://comunidadedoestagio.com/blog/os-perigos-da-antropomorfizacao-de-empresas-na-internet
Sunday, March 14, 2021





Saturday, March 13, 2021

Laws of Software Architecture
Everything in software architecture is a trade-off.
-First Law of Software Architecture
Why is more important than how.
-Second Law of Software Architecture
Invalidating Axioms About Software Architecture
We also address the critically important issue of trade-off analysis. As a software developer, it’s easy to become enamored with a particular technology or approach. But architects must always soberly assess the good, bad, and ugly of every choice, and virtually nothing in the real world offers convenient binary choices—everything is a trade-off.

Friday, March 12, 2021


Wednesday, March 10, 2021
Maior palavra do idioma português
Pneumoultramicroscopicossilicovulcanoconiótico
adjetivo Relacionado com a doença que ataca os pulmões, causada pela inalação de cinzas vulcânicas, cinzas provenientes de vulcões. Refere-se à pneumoultramicroscopicossilicovulcanoconiose (doença). substantivo masculino Indivíduo portador dessa doença.
Sunday, March 07, 2021












Recommended Software Process Steps
- Requirements engineering
- Gather user stories from all stakeholders.
- Have stakeholders describe acceptance criteria user stories.
- Preliminary architectural design
- Make use of paper prototypes and models.
- Assess alternatives using nonfunctional requirements.
- Document architecture design decisions.
- Estimate required project resources
- Use historic data to estimate time to complete each user story.
- Organize the user stories into sprints.
- Determine the number of sprints needed to complete the product.
- Revise the time estimates as use stories are added or deleted.
- Construct first prototype
- Select subset of user stories most important to stakeholders.
- Create paper prototype as part of the design process.
- Design a user interface prototype with inputs and outputs.
- Engineer the algorithms needed for first prototypes.
- Prototype with deployment in mind.
- Evaluate prototype
- Create test cases while prototype is being designed.
- Test prototype using appropriate users.
- Capture stakeholder feedback for use in revision process.
- Go, no-go decision
- Determine the quality of the current prototype.
- Revise time and cost estimates for completing development.
- Determine the risk of failing to meet stakeholder expectations.
- Get commitment to continue development.
- Evolve system
- Define new prototype scope.
- Construct new prototype.
- Evaluate new prototype and include regression testing.
- Assess risks associated with continuing evolution.
- Release prototype
- Perform acceptance testing.
- Document defects identified.
- Share quality risks with management.
- Maintain software
- Understand code before making changes.
- Test software after making changes.
- Document changes.
- Communicate known defects and risks to all stakeholders.
Distribution of maintenance effort

SWEBOK refers to the Software Engineering Body of Knowledge, which can be accessed using the following link: https://www.computer.org/web/swebok/v3.
What Is Agility?
The underlying ideas that guide agile development led to the development of agile methods designed to overcome perceived and actual weaknesses in conventional software engineering. Agile development can provide important benefits, but it may not be applicable to all projects, all products, all people, and all situations. It is also not antithetical to solid software engineering practice and can be applied as an overriding philosophy for all software work.
In the modern economy, it is often difficult or impossible to predict how a computerbased system (e.g., a mobile application) will evolve as time passes. Market conditions change rapidly, end-user needs evolve, and new competitive threats emerge without warning. In many situations, you won’t be able to define requirements fully before the project begins. You must be agile enough to respond to a fluid business environment.
Fluidity implies change, and change is expensive—particularly if it is uncontrolled or poorly managed. One of the most compelling characteristics of the agile approach is its ability to reduce the costs of change through the software process. In a thought-provoking book on agile software development, Alistair Cockburn [Coc02] argues that the prescriptive process models have a major failing: they forget the frailties of the people who build computer software.
Software engineers are not robots. They exhibit great variation in working styles and significant differences in skill level, creativity, orderliness, consistency, and spontaneity. Some communicate well in written form, others do not. If process models are to work, they must provide a realistic mechanism for encouraging the discipline that is necessary, or they must be characterized in a manner that shows “tolerance” for the people who do software engineering work.



Friday, March 05, 2021

Wednesday, March 03, 2021

The dual world
Philosophy says what is right or wrong
Science says what is true or false
Engineering says what works and what doesn't
Art says what is beautiful or not
And so on ...
Subscribe to:
Comments (Atom)